
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
This is an archived page. To see the latest version, please visit Job Openings and Labor Turnover Survey: Calculation.
The Job Openings and Labor Turnover Survey (JOLTS) program uses the following methodologies to generate the estimates. The methodologies below are presented in terms of their order of operation.
A multiplicative nonresponse adjustment factor (NRAF) is used to inflate the weight of respondents in an estimation cell to adjust for nonrespondents. The weight of all nonrespondents is redistributed among the respondents to preserve the total weighted employment of the cell. The NRAF is calculated by dividing the weighted frame employment of the viable establishments in the cell by the weighted frame employment of usable sample units in the cell:
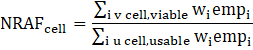
where,
the subscript “cell” denotes the industry division, census region, and establishment size,
i designates the ith establishment,
v designates viable units, that is, those in-scope sampled units which are capable of reporting; that is, sampled units that are not out of business, out of scope, or duplicates,
u designates usable units, a subset of viable units, that is those units which responded to the JOLTS with usable data,
empi is the sample frame employment of the ith unit, and
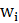 is the sampling weight of the ith unit.
is the sampling weight of the ith unit.
Note: By definition, NRAF > 1 as the number of usable units is less than or equal to the number of viable units.
Item nonresponse occurs when a respondent reports some of the JOLTS data elements, but not others.
To impute data elements that have not been reported, the JOLTS program classifies establishments based on their employment dynamic—expanding, stable, or contracting—and imputes items within those groups. Thus, expanding establishments donate estimated item values to expanding establishments, stable to stable, and contracting to contracting. Drawing imputed values from a model-based donor distribution derived from reported data within a dynamic grouping reduces variation in the estimates. The imputation model also ensures that imputed data within each dynamic group is consistent with reported data within the group without biasing the means of the data elements or substantially lowering their variances.
A Horvitz–Thompson estimator with a ratio adjustment is used to produce estimates of levels of surveyed data elements at different degrees of geographical and industrial detail. To calculate the estimated level for each data element for a given month in a basic estimation cell, the following steps are performed:
To ratio-adjust JOLTS employment to Current Employment Statistics (CES) employment, it is necessary to calculate the Summed Weighted Total Employment (SWTE) for each JOLTS industry division within a census region (region/id).
The final weighted JOLTS employment for each record in a region/id cell is calculated by multiplying the following: sample weight* NRAF*reported JOLTS employment for that record.
The SWTE is calculated in each region/id cell by summing the final weighted JOLTS employment in each region/id cell.
The benchmark factor (BMF) is calculated by dividing CES employment (at the region/id level) by the SWTE (at the region/id level).
The CES program produces an industry employment estimate using a much larger sample than JOLTS.
Ratio adjusting JOLTS data element estimates to CES industry employment increases the statistical reliability of all JOLTS data element estimates:
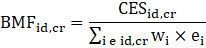
where,
the subscript id,cr denotes industry division and census region,
BMFid,cr is the benchmark factor for industry and census region,
CESid,cr designates industry division and census region employment,
wi is the sampling weight reflecting all adjustments (NRAF, atypical data adjustment, etc.) for sample unit i, and
ei = reported employment from sample unit i.
Thus, the equation used to compute the estimate of a data element is
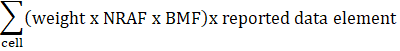
where weight is the recomputed (that is, reweight) sampling weight.
Winsorization is a statistical process commonly used to reset outlier values to a predetermined threshold value, also called the cutoff value. In JOLTS, an independent cutoff value is established for each employment size and data element (job openings, hires, etc.). Any reported value exceeding the cutoff is reset to the cutoff value.
As with any sample survey, the JOLTS sample can only be as current as its sampling frame. The time lag from the birth of an establishment until its appearance in the sampling frame is approximately 1 year. In addition, many new establishments fail within the first year. Because new and short-lived universe establishments cannot be reflected in the sampling frame immediately, the JOLTS sample cannot capture job openings, hires, and separations from these establishments during their early existence. BLS has developed a model for estimating birth and death activity in current months by examining data on birth and death activity in previous years as collected by the Quarterly Census of Employment and Wages (QCEW), and projecting forward to the present using over-the-year change in the Current Employment Statistics (CES). The birth–death model also uses historical JOLTS data to calculate the amount of churn (meaning the rates of hires and separations) that exists in establishments of various sizes. The model then combines the calculated churn with the projected employment change to estimate the number of hires and separations that take place in these establishments that cannot be measured through sampling.
The model-based estimate of total separations is distributed to the three components of total separations—quits, layoffs and discharges, and other separations—in proportion to their contribution to the sample-based estimate of total separations. In addition, job openings in the establishments modeled are estimated by computing the ratio of openings to hires in the collected data and applying that ratio to the modeled hires. The estimates of job openings, hires, and separations produced by the birth–death model are then added to the sample-based estimates produced from the survey to arrive at the estimates for job openings, hires, and separations.
Estimates review and outlier selection. Estimates are examined for atypical or large movements, and values that appear questionable are flagged for verification. Microdata are examined in the verification process. If microdata is confirmed to be atypical, outliers are then selected. Outliers selected manually have their weight changed to 1.0 and are disqualified as acting as donors during item imputation. After estimates review, the not seasonally adjusted estimates are re-run and again reviewed.
The JOLTS figure for hires minus separations should be comparable to the CES over-the-month net employment change. Because of its large sample size and annual benchmarking to universe counts of employment from the QCEW program, the CES series is considered a highly accurate measure of net employment change. However, definitional differences, as well as sampling and nonsampling errors between the two surveys, have caused JOLTS to diverge from the CES survey over time. To limit the divergence and to improve the quality of the JOLTS hires and separations series, BLS implemented a monthly alignment method. Simply put, there are four steps to this method: seasonally adjust, align, back out the seasonal adjustment factors, and re-seasonally adjust.
The monthly alignment method applies the seasonally adjusted CES employment trend to the seasonally adjusted JOLTS implied employment trend (hires minus separations), keeping the two trends consistent while preserving the seasonality of the JOLTS data. First, the two series are seasonally adjusted and the difference between the JOLTS implied employment trend and the CES net employment change is calculated. Next, the JOLTS implied employment trend is updated to equal the CES net employment change through a proportional adjustment. This proportional adjustment procedure modifies the two components (hires and separations) in proportion to their contribution to the total churn (hires plus separations). For example, if the hires estimate makes up 40 percent of the churn for a given month, it will receive 40 percent, and separations will receive 60 percent, of the needed adjustment.
The following is an example of the alignment method:
Let Hires denote the number of hires.
Let Seps denote the number of separations.
Let Cesemp represent CES employment.
Hires_sa = 40
Seps_sa = 60
D Cesemp = –25
In this case, hires minus separations does not equal the change in CES employment.
Then,
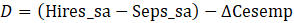
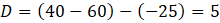
where D denotes the divergence between CES employment trend and JOLTS hires minus separations.
Let PAHires_sa denote the proportionally adjusted seasonally adjusted hires.
Let PASeps_sa denote the proportionally adjusted seasonally adjusted separations.
Let Hires_A denote aligned hires.
Let Seps_A denote aligned separations.
Then,
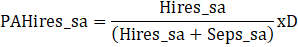
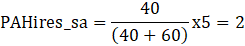
And,
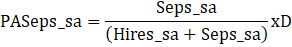
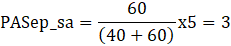
Finally,
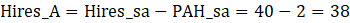
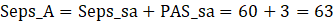
This yields the following:
Seasonally adjusted hires minus seasonally adjusted separations is equal to the change in CES employment.
Resulting in,
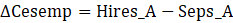
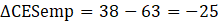
Job openings are aligned based on the ratio of job openings to hires from the not seasonally adjusted estimates. This ratio of job openings to hires is applied to the updated hires to compute the updated job openings. The adjusted job openings, hires, and separations are converted back to not seasonally adjusted data by reversing the application of the original seasonal adjustment factors.
Example:
Let JO denote job openings.
Let JO_A denote aligned job openings.
JO=11
To obtain aligned job openings,
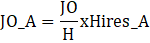
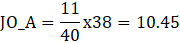
The monthly alignment procedure assures a close match of the JOLTS implied employment trend with the CES employment trend for the not seasonally adjusted data. The aligned not seasonally adjusted estimates are then published.
After alignment, the X-13-ARIMA-SEATS seasonal adjustment program is used to seasonally adjust the JOLTS series. Seasonal adjustment is the process of estimating and removing periodic fluctuations caused by events such as weather, holidays, and the beginning and ending of the school year. Seasonal adjustment makes it easier to observe fundamental changes in data series, particularly those associated with general economic expansions and contractions. Each month, a concurrent seasonal adjustment methodology uses all relevant data, up to and including the data for the current month, to calculate new seasonal adjustment factors.
Moving averages are used as seasonal filters in seasonal adjustment. JOLTS seasonal adjustment includes both additive and multiplicative models, as well as REGARIMA (regression with autocorrelated errors) modeling, to improve the seasonal adjustment factors at the beginning and end of the series and to detect and adjust for outliers in the series.
The estimation of sample variance for the JOLTS survey is accomplished by using the balanced half samples (BHS) method. This replication technique uses half samples of the original sample to calculate estimates. The sample variance is calculated by measuring the variability of the subsample estimates. The sample units in each cell—where a cell is based on region, industry, and size class—are divided into two random groups. The basic BHS method is applied to both groups. The cells are subdivided systematically, in the same order as the initial sample selection. Weights for units in the half sample are multiplied by a factor of 1 + α, whereas weights for units not in the half sample are multiplied by a factor of 1 – α , where
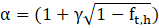
in which γ is Fay’s factor (0.5). Fay’s method is a generalized form of BHS which uses the full sample but with unequal weighting for each half-sample. Sample weights are adjusted by α in the formula above by setting γ= 0.5 for those units outside the half-sample and are adjusted by α by setting γ=1.5 for those units within the half-sample.
The finite population correction (f) factor is calculated as
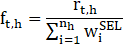
Where,
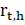 is the number of units reporting employment in allocation stratum h at time t,
is the number of units reporting employment in allocation stratum h at time t,
nh is the number of sample units in allocation stratum h,
and the variable wiSEL is the sample selection weight of sample unit i.
The JOLTS data are revised annually to reflect annual updates to the CES employment estimates. The JOLTS employment levels (not published) are ratio-adjusted to the CES employment levels, and the resulting ratios are applied to all JOLTS data elements. This annual benchmarking process results in revisions to both the seasonally adjusted and not seasonally adjusted JOLTS data series, for the period since the last benchmark was established. The seasonally adjusted data are recalculated for the most recent 5 years in order to reflect updated seasonal adjustment factors. Further, the alignment methodology creates a dependency of the not seasonally adjusted estimates on the seasonal adjustment process. Therefore, the data series that are not seasonally adjusted are also recalculated for the most recent 5 years in order to reflect the effect of the updated seasonal adjustment factors on the alignment process.
Unit and item response rates are tracked on a monthly basis to measure data quality and usability. Refusal rates, initiation rates, and collection rates are also calculated and monitored.
JOLTS estimates are subject to two types of error: sampling error and nonsampling error.
Sampling error can result when a sample, rather than an entire population, is surveyed. There is a chance that the sample estimates may differ from the true population values they represent. The exact difference, or sampling error, varies with the particular sample selected, and this variability is measured by the standard error of the estimate. BLS analysis is generally conducted at the 90-percent level of confidence. This means that there is a 90-percent chance that the true population mean will fall into the interval created by the sample mean plus or minus 1.65 standard errors. Estimates of median standard errors are released on a monthly basis as part of the significant change tables on the JOLTS webpage and are available upon request. Standard errors are updated annually with the most recent 5 years of data.
The JOLTS estimates are also affected by nonsampling error. Nonsampling error can occur for many reasons, including the failure to include a segment of the population, the inability to obtain data from all units in the sample, the inability or unwillingness of respondents to provide data on a timely basis, mistakes made by respondents, errors made in the collection or processing of the data, and errors from the employment benchmark data used in estimation.
The JOLTS program uses quality control procedures to reduce nonsampling error in the survey’s design. See the Data Sources section.