
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
The LAUS program uses a hierarchy of nonsurvey methodologies to produce monthly estimates of the civilian labor force, employed persons, unemployed persons, and unemployment rates for approximately 7,500 subnational areas.Estimates for states
Monthly labor force data for all states and the District of Columbia are based on the time-series approach to sample survey data.1 This approach reduces the high variability in monthly Current Population Survey (CPS) estimates that results from the small CPS sample sizes for the states and the District. Actual monthly CPS sample estimates are represented in signal-plus-noise form as the sum of a stochastic true labor force series (signal) and error (noise) generated by sampling only a portion of the total population and expressed as
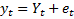
where: 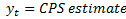
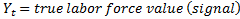
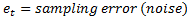 .
.
The signal is represented by a time-series model that incorporates historical relationships in the monthly CPS estimates along with auxiliary data from the state unemployment insurance (UI) systems and the Current Employment Statistics (CES) survey. This time-series model is combined with a noise model that reflects key characteristics of the sampling error to produce estimates of the true labor force values.2 This estimator is optimal under the model assumptions and has been shown by Bell and Hillmer3 to be design-consistent under general conditions.
Two models—one for the employment level and a second for the unemployment level—were developed for each state on the basis of data from 1976 through present. The labor force level and unemployment rate are derived from the employment and unemployment measures produced by the two respective models. The signals for both models are based on a basic structural model that decomposes a series into stochastic trend-cycle (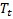 ), seasonal (
), seasonal (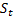 ), and irregular (
), and irregular (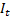 ) components.4 The model is of the following form:
) components.4 The model is of the following form:
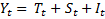
The trend-cycle and seasonal components have mutually independent normal disturbance terms that cause them to drift slowly over time. The variances of these disturbances constitute the hyperparameters of the signal and determine the properties of the individual components. A positive variance for a component implies that it is stochastic (meaning it is not perfectly predictable from past history), and a zero variance implies deterministic behavior (that is, a fixed pattern over time). The irregular component is treated as an uncorrelated zero-mean disturbance with fixed variance.
The models use information from state CPS time series. A natural extension of the structural model is to allow one or more of the unobserved components of the signal to be related to corresponding components in another series. State-specific monthly covariates have been developed from auxiliary data sources: UI claims from the federal-state UI system are used for the unemployment model, and nonagricultural payroll employment estimates from the CES program are used for the employment model. The model for the regressor Xt, follows the same basic structural form as for Yt, with stochastic trend, seasonal, and irregular components.
The current models use a regressor format. CES employment and UI claims are seasonally adjusted with their respective univariate model, and then each is used as the regressor variable in its respective model of employment or unemployment.
The second major component of the signal-plus-noise model deals with CPS sampling errors.5 Because of this survey's complex design, the behavior of the observed sample estimates differs in important ways from that of the true values. Sampled households rotate in and out of the CPS over a period of 16 months, such that 75 percent of the sample from month to month consists of the same households and 50 percent from year to year. (See the Current Population Survey Handbook of Methods chapter.) Also, sample redesigns and large fluctuations in the size of the labor force cause changes in the variance of the estimates. These two features of the CPS—an overlapping sample design and changes in reliability—induce strong positive autocorrelation and heteroskedasticity in the standard errors. These characteristics can seriously contaminate estimates of the true labor force if the sampling error is ignored in the estimation process. For this reason, it is important to specify a model of the standard error process and combine it with the model of the signal, to estimate the unobserved components of the CPS. The standard error model is specified as
et = γt e*t
with 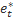 reflecting the autocovariance structure, assumed to follow an autoregressive moving average (ARMA) process, and γt representing a changing variance over time. The parameters of the ARMA model are derived from sampling error autocorrelations developed independently of the time-series model from design-based information. The CPS error variances are estimated using the method of generalized variance functions.6
reflecting the autocovariance structure, assumed to follow an autoregressive moving average (ARMA) process, and γt representing a changing variance over time. The parameters of the ARMA model are derived from sampling error autocorrelations developed independently of the time-series model from design-based information. The CPS error variances are estimated using the method of generalized variance functions.6
The unknown hyperparameters of the signal are estimated by maximum likelihood, using the Kalman filter algorithm. Given these estimated hyperparameters, the Kalman filter is used to decompose the observed CPS into its signal and noise components. This algorithm efficiently updates the model estimates as new data become available each month. For the latest month, the Kalman filter calculates estimates on the basis of all available data but does not revise estimates for the previous months with the latest data. Previous estimates are updated by a Kalman filter smoother, which revises a given period's estimate by using all data available, both before and after the month. This smoothing procedure is performed only at the end of each year.
LAUS model estimates are adjusted using a process of real-time benchmarking, whereby each month, state model estimates are controlled to the CPS national estimates of employment and unemployment, such that the not-seasonally-adjusted estimates for all states and the District of Columbia sum to the national not seasonally adjusted estimates. By forcing state model estimates to add to current monthly national CPS estimates, real-time protection is provided for the models because the benchmarked estimators reflect changes in the labor force as they occur. Another benefit of benchmarking is to ensure comparability between estimates at different levels of geography.
Real-time benchmarking occurs as part of the estimation process. First, employment and unemployment estimates for census divisions are created from CPS-only univariate signal-plus-noise models that are controlled to the national not-seasonally-adjusted CPS estimates. Then, state models are estimated and controlled to the appropriate division estimates.
State-specific outliers are external shocks that represent departures from the normal behavior of a series. The effect of an outlier specific to a given state is not spread to other states. This is accomplished by estimating outliers at the state level and then aggregating these effects to the appropriate division level and the national level. The outliers are subtracted from the state, division, and national CPS series. The division models are estimated from the adjusted division-level CPS data and then benchmarked to the national CPS with the same outlier effects removed. The states are estimated from the adjusted state CPS data and benchmarked in the same manner to the adjusted benchmarked division model estimates. Once benchmarking is complete, the outlier is added back to the state, division, and national totals, preserving additivity.
In 2010, a smoothed seasonal adjustment process was introduced to reduce the number of spurious fluctuations in the seasonally adjusted estimates due primarily to noise introduced in real-time benchmarking. State labor force estimates were smoothed with the use of the Henderson trend filter, which uses weighted moving averages to suppress irregular fluctuations in the seasonally adjusted series, leaving the trend more visible. Two-sided, symmetric moving averages (up to 13 months in length) were used to smooth the historical series, while a one-sided, asymmetric (7-month) average was used in real time.
The fourth generation of models decompose the estimates of employed and unemployed persons into trend-cycle, seasonal, and irregular components. The trend component of each measure is then smoothed using a Trend-Cycle Cascade Filter, which combines the Henderson trend filter with a seasonal filter. This combined filter suppresses variability due to real-time benchmarking while simultaneously removing any residual seasonality that may be present in the series. The resulting smoothed seasonally adjusted unemployment rate estimates are published on the BLS website and analyzed in the monthly state news release. During estimation for the current year, the smoothed-seasonally adjusted estimates for a given month are created using an asymmetric filter that incorporates information from previous observations only. For annual revisions, historical data are smoothed using a two-sided filter.
Estimates for counties (or cities and towns in the New England states) are developed through a building block approach known as the Handbook method. An exception is seven substate areas that are modeled using the same estimation techniques as the states. Data for multicounty areas are summed from the Handbook-based data for their component counties, while estimates for subcounty areas, such as cities, are produced using disaggregation techniques.
In addition to the state models, there are seven substate areas that are modeled utilizing the same regressor structure as the state estimates. Estimates for Los Angeles County, New York City, and the balances of California and New York State are each modeled. Estimates for the state of California are then derived by summing the estimates for Los Angeles County and the balance of California. Similarly, estimates for New York State are derived by summing the estimates for New York City and the balance of New York State. Model-based estimates also are produced for five additional substate areas and their respective balances of state: the Chicago-Naperville-Arlington Heights, IL Metropolitan Division; the Cleveland-Elyria, OH Metropolitan Statistical Area; the Detroit-Warren-Dearborn, MI Metropolitan Statistical Area; the Miami-Miami Beach-Kendall, FL Metropolitan Division; and the Seattle-Bellevue-Everett, WA Metropolitan Division. For these five areas, substate and balance-of-state estimates are controlled to their respective state totals.
With the exception of the seven substate area models discussed, the Handbook method is used for substate estimation. This method is an effort to use available information to create employment and unemployment estimates for an area that are comparable to what would be produced by a representative sample of households in that area, without the expense of conducting a large labor force survey like the CPS. The method presents a series of estimating building blocks, for which categories of employed and unemployed workers are estimated and then summed.
The total employment estimate for a particular area is based on data from several sources. The two main sources are the CES survey, the state-designed monthly survey of establishments, and the Quarterly Census of Employment and Wages (QCEW), a universe count of employment covered by the UI system. (See the QCEW chapter.) These sources are designed to produce estimates of the total number of employees on payrolls in nonfarm industries for a particular area.
Because employment estimates from these sources are based on the location of the establishment, these place-of-work estimates must be adjusted to reflect the place-of-residence concept used in the CPS survey of households. Resident employment includes workers living and working in the same area and also those who work in other areas within commuting distance. Estimates of resident employment should, therefore, reflect establishment employment changes in those related commutation areas as well. LAUS uses dynamic residency ratios to provide this adjustment, using American Community Survey (ACS) commutation data. Separate residency adjustment ratios are developed for each estimating area and additional areas with at least 10 percent of residents commuting into the estimating area for work. Ratios for each of the commuting areas are multiplied by their respective monthly nonfarm jobs estimates to produce estimates of estimating area residents who work in each of the commuting areas. Separate commuting area estimates are summed to create a total of the resident nonfarm wage and salary employment for the area. This adjustment also accounts for multiple jobholding and unpaid absences in the payroll employment estimates. Next, these nonagricultural wage and salary employment estimates are disaggregated to the county level or the Minor Civil Division (MCD) level in New England using ACS nonagricultural wage and salary employment ratios.
Estimates for employment not represented in the establishment series—agricultural workers and nonfarm self-employed workers, unpaid family workers, and private household workers—are derived by disaggregation using data from the CPS and the ACS. These components, plus the wage and salary component, represent total handbook employment. To develop estimates for employment not covered by the establishment series, the state-level 5-year weighted-average CPS estimates of nonfarm self-employed, unpaid family, and private household workers are controlled to the national CPS all-other employment total for the current month. All-other employment data from the ACS are then used to estimate shares for allocating the state-level CPS all-other employment data to substate areas. Agricultural employment estimates also are developed from CPS and ACS data. Again, the 5-year weighted-average CPS statewide agricultural employment is controlled to the national CPS agricultural employment total for the current month, then ACS agricultural employment data are used to distribute the CPS monthly, 5-year weighted-average CPS statewide agricultural employment to substate areas.
The estimate of unemployment is an aggregate of the estimates for each of the two building-block categories: those covered by the UI system and those outside its scope (called the noncovered). The covered category consists of people who are currently receiving UI benefits and people who have exhausted their benefits. The noncovered category consists of people who are ineligible to receive UI benefits.
A count of the covered unemployed who collected UI benefits during the reference week (the week of the 12th) and also had no earnings due to employment is obtained directly from state, federal, and railroad unemployment programs. Estimates of unemployed people who have exhausted their benefits (known as exhaustees) are based upon the number of claimants who received their final payments in the week before the reference week, plus an estimate of exhaustees from previous periods who are still unemployed. This calculation involves estimating the percentage of long-term unemployed who continue to remain unemployed each week and applying that percentage to the exhaustee pool.
Noncovered unemployed are those people who are not in the scope of the UI system. Many of the unemployed were not employed immediately before their current spell of unemployment and, thus, did not meet the wage and employment experience requirements to qualify for UI compensation. Because UI compensation is not a criterion for determining unemployment status in the CPS, these individuals, known as entrants to the labor force, are counted as unemployed and included in LAUS estimates.
Unemployed entrants are divided into two groups: new entrants and reentrants. New entrants are individuals who have entered the labor force for the first time. Reentrants are individuals who have reentered the labor force after a period of neither employment nor unemployment. Both new entrants and reentrants are estimated from state-level CPS data on a 5-year weighted average for each month. Then, the averages for each state are controlled to the corresponding national total for the current month. Next, these adjusted statewide entrant totals are distributed to each county (minor civil division, or MCD, in New England), using population shares based on the latest annual July-1 population estimates from the Census Bureau. A county new entrant estimate is calculated as its share of the state population ages 16–19, multiplied by the total statewide new entrant estimate. Reentrants are estimated by a similar procedure, using each county’s share of the state population ages 20 years and older and the statewide reentrant total.
Each month, Handbook estimates are prepared for counties or MCDs that exhaust each state geographically. To obtain an estimate for a given area, a Handbook share is computed for that area; this is defined as the ratio of the area's Handbook estimate to the sum of the Handbook estimates for all counties or MCDs in the state. The area's Handbook share is then multiplied by the current statewide modeled estimate to produce the final adjusted county or MCD estimate of employment:
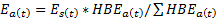
where
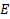 = total employment
= total employment
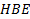 = handbook employment
= handbook employment
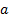 = area
= area
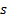 = state
= state
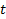 = time.
= time.
The additivity procedure for unemployment is analogous:
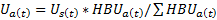
where
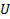 = total unemployment
= total unemployment
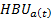 = handbook unemployment
= handbook unemployment
= area
= state
= time.
Total employment and unemployment estimates for counties and MCDs then are aggregated to create estimates for multi-entity labor markets areas and related geography, such as metropolitan and micropolitan areas.
Current labor force estimates at the subcounty level are required by several federal allocation programs. However, the Handbook method was not designed for these small areas because the data required to compute independent handbook estimates generally are not available. Based on data availability, two alternative methods are used to disaggregate the county estimates to the subarea level.
The population- and claims-based method is the standard technique for disaggregation. If residence-based UI claims data are available for the subareas within the county, the ratio of the subarea to the total number of claims within the county is used to disaggregate the estimate of covered unemployed to the subarea level. The new entrant and reentrant components of unemployed are disaggregated from the county using subarea shares of county population for the 16-to-19 age group and 20 and older age groups, respectively. Employment is disaggregated using distributions calculated from the ACS that are indexed to the July-1 population estimates for the reference year. This combination of techniques is used to derive estimates for cities with populations of more than 25,000.
If the necessary UI claims data are not available at the subarea level, the ACS-share method is used. This method uses distributions calculated from the ACS that are indexed to the July-1 population estimates for the reference year for both employment and unemployment disaggregation.
Employment and unemployment estimates for metropolitan areas and metropolitan divisions are seasonally adjusted each month, using a model-based approach known as SEATS, which stands for Signal Extraction in ARIMA (Auto Regressive Integrated Moving Average) Time Series. The trend estimate, which is derived from the SEATS decomposition of the series into its trend, seasonal, and irregular components, is the seasonally adjusted LAUS estimate. These data are published via supplemental tables on the BLS website.
At the end of each year, LAUS conducts a review of model performance. States provide information about their economies. Month-to-month movements and observations are examined to determine if they are reflective of economic events or if any should be considered outliers.
At the beginning of each year, LAUS receives new population controls from the Census Bureau. CPS estimates for states, census divisions, and the United States are revised, using these new estimates of the civilian noninstitutional population ages 16 and older. Revisions to state model inputs—specifically, CES and UI—also are received. State and substate models then are reestimated to incorporate changes in inputs and population controls, using all data in the series. Revised statewide estimates are controlled to updated census division models that sum to national totals, all reflecting the new population controls. (The official U.S. totals generally are not revised to reflect new population estimates. Rather, the new controls are implemented in January.)
Substate estimates are revised to incorporate any changes in the inputs, such as revisions in the employment estimates based on place of work, revisions to UI claims data, and updated historical relationships. Area Handbook estimates then are revised and readjusted to sum to the revised state estimates of employment and unemployment. Areas for which the estimates are disaggregated are revised, using updated population estimates for the indexing of disaggregation ratios.
Approximately once per decade, the LAUS program conducts major redesigns of its methodology in order to continue to improve labor force estimates for states and substate areas. In 2015, a fourth generation of time-series models was introduced, and improvements were made to several aspects of the Handbook methodology, including the incorporation of data from the ACS. The state series was reestimated back to the beginning of the series in 1976, and substate estimates were comprehensively revised back to 2010. See “Changes to state and local area labor force estimation in 2015” for documentation relating to the redesign.
Concurrent with the methodological changes each decade, the LAUS program also implements new census-based federal statistical area delineations, as issued by the Office of Management and Budget (OMB). For more information and documentation on the delineations based on the 2010 Census that were implemented in 2015, see https://www.bls.gov/lau/lausmsa.htm.
1 W.R. Bell, and S.C. Hillmer, "The Time Series Approach to Estimation for Repeated Surveys," Survey Methodology, 1990, pp. 195–215; and A.J. Scott, T.M.F. Smith, and R.G. Jones, "Analysis of Repeated Surveys Using Time Series Methods, "Journal of the American Statistical Association, 1974, pp. 674–678.
2 Richard B. Tiller, "Model-Based Labor Force estimates for Sub-National Areas with large Survey Errors" (U.S. Bureau of Labor Statistics, 2006), https://www.bls.gov/osmr/research-papers/2006/pdf/st060010.pdf .
3 W.R. Bell and S.C. Hillmer, "The Time Series Approach to Estimation for Repeated Surveys," Survey Methodology,1990 pp. 195–215.
4 A.C. Harvey, Forecasting, Structural Time Series Models, and the Kalman Filter (New York: Cambridge University Press, 1989).
5 Richard B. Tiller, "Time Series Modeling of Sample Survey Data from the U.S. Current Population Survey," Journal of Official Statistics, 1992, pp. 149–166.
6 T.S. Zimmerman, and E. Robison, "Report on Revised State GVF Parameters for CPS Monthly Employment and Unemployment Estimates in States, District of Columbia, and Four Substate Areas: 1976-Present," BLS internal memorandum, 1996.