
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
The Occupational Requirements Survey (ORS) calculates categorical and continuous estimates of job requirements by occupation and occupational group. Categorical estimates provide the percentage of workers by job requirement. For many of the categorical estimates, the ORS also identifies the mode within a categorical grouping. Continuous estimates measure the average (or mean in hours, days, percentage of workday or pounds) or percentile for the job requirement.
See appendix A at the end of this section for a full list of published occupational requirements as well as a list of corresponding estimate types.
This section includes the formulas used to calculate the ORS estimates.
The formula for the percentage of workers with a given job requirement in the domain (occupation or occupational group) is
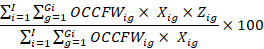
where
I is the total number of establishments,
Gi is the total number of sampled jobs in establishment i,
i is the establishment,
g is the occupation within establishment i,
OCCFWig is the final sampled job weight for occupation g in establishment i,
Xig is 1 if sampled job ig meets the condition set in the domain (denominator) condition and 0 otherwise, and
Zig is 1 if sampled job ig meets the condition set in the requirement condition and 0 otherwise.
The formula for the average (mean) estimate of a job requirement is
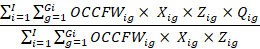
where
I is the total number of establishments,
Gi is the total number of sampled jobs in establishment i,
i is the establishment,
g is the occupation within establishment i,
OCCFWig is the final sampled job weight for occupation g in establishment i,
Xig is 1 if worker ig meets the condition set in the domain (denominator) condition and 0 otherwise,
Zig is 1 if worker ig meets the condition set in the requirement condition and 0 otherwise, and
Qig is the value of a quantity for a specific requirement for occupation g in establishment i.
The 10th, 25th, 50th (median), 75th, and 90th, percentiles are calculated. The pth percentile is the value Qig, where the value of a quantity is for a specific category for occupation g in establishment i, such that
It is possible that there is no specific sampled job ig for which both properties hold. This occurs when there exists a sampled job for which the OCCFWig of records whose value is less than Qig equals p percent of the total weighted sampled job employment. In that situation, the pth percentile is the average (mean) of Qig and the value of the sampled job with the next lowest value.
Where possible, ORS estimates are reported as point estimates; however, some estimates, which would otherwise go unpublished because of not meeting confidentiality or reliability publication criteria, are published as range values. Ranges use an estimate's confidence interval to provide either a value that the estimate is less than or a value that the estimate is greater than. These ranges are also used for categorical estimates (for example, the requirement is present or not present) that are equal to 0 or 100 percent where a confidence interval is not possible.
Duration corresponds to the time associated with occupational requirements needed to perform critical tasks. Exhibit 1 provides the duration levels with the corresponding percent or fraction of the workday that workers perform physical demands or are exposed to environmental conditions. See appendix B at the end of this section for a list of job requirements with associated duration.
| ||||||||||||||
The ORS calculates a percentage-of-workers estimate for each duration level. While most physical demands and environmental conditions are measured using duration levels (categorical measures), some physical demands and education, training, and experience requirements are captured as continuous measures. For requirements measured continuously, estimates are available as averages (mean) and percentile estimates. For example, the ORS measures sitting in hours and the average (mean) and percentile estimates (10th, 25th, 50th, 75th, and 90th percentiles) are calculated for both hours and the percentage of the workday spent sitting for a specific occupation or occupational group.
Although the ORS calculates most job requirement estimates from establishment responses about selected jobs' various tasks, some require an additional level of calculation. One of these is the specific vocational preparation (SVP) level, which is the amount of preparation time required for the worker to develop the skills needed to perform the job. The job requirements that contribute to the SVP are minimum education, nondegree credentials, prior work experience, and on-the-job training. The preparation time associated with these requirements is then aggregated and used to determine the SVP level needed for the job. (See exhibit 2.)
Concurrent time due to credentials necessary for jobs that also require minimum formal education level, experience, or on-the-job training are not included separately in SVP. Concurrent time is reflected in the education, training, and experience requirements where the time overlaps with time necessary to obtain licenses, certifications, educational certificates, apprenticeships, or other non-degree credentials.
| ||||||||||||||||||||||
The percentage of workers required and not required to read or write (in any language) in order to perform critical tasks is calculated when no minimum formal education is required. Since literacy requirements are only collected when there is no formal minimum education required, the sum of literacy requirements equal the percentage of workers with no minimum formal education requirement. When a high school diploma or higher degree is required, literacy requirements are not calculated.
Strength levels are derived from several physical requirements. The estimates reflect the amount of weight workers are required to lift or carry, how often, and whether standing or walking is required to perform critical tasks in the workday. The strength levels show whether jobs are considered sedentary, light work, medium work, heavy work, and very heavy work. (See exhibit 3.)
As noted, there are special cases for strength. In instances where field economists cannot determine certain job requirements from the respondent, they record these data as "unknown" and strength level is derived through imputation. See the section benchmarking, weighting, and imputation for more information. Estimate relationshipsIn some cases, the relationships between ORS estimates are more complex than a job requirement being present or not present. Relationships are shown through the category and additive groups assigned to estimates in the complete dataset. The category code is the same for all related estimates. For example, all sitting estimates have the same category code. The additive code is used to show how these estimates sum together. Sometimes estimates sum to 100 percent, whereas others sum to another estimate instead of 100 percent. For example, the percentage of workers utilizing and not utilizing personal protective equipment (PPE) to mitigate risks that go along with exposure to heights together sum to the percentage of workers exposed to heights. See appendix C for more information on the relationships shown in the additive codes. Benchmarking, weighting, and imputationThe ORS program addresses establishment refusals, item nonresponse, as well as out of business and out of scope units. The ORS program adjusts the weights of the responding establishments during the estimation process to address nonresponse (specifically unit nonresponse). Imputation is used to address item nonresponse, which is when an establishment responds to the survey but is unable or unwilling to provide all the occupational requirement data needed for a given sampled job. Benchmarking adjusts final survey weights to reflect the current employment distribution in the economy. BenchmarkingThe ORS uses benchmarking to adjust the weight of each collected occupation in the survey and to match the most current distribution of employment by several establishment and occupational characteristics. The ORS establishment sample is adjusted according to data from the Quarterly Census of Employment and Wages (QCEW). The QCEW, information from the Railroad Retirement Board, and the Occupational Employment and Wage Statistics (OEWS) survey provide historical employment data needed for the benchmarking process, but since these sources do not have current employment data, the ORS also uses the Current Employment Statistics (CES) survey to make an adjustment to employment. The benchmarking process updates the initial employment weights, assigned during sampling, by current employment. Benchmarking ensures that survey estimates reflect the most current employment distribution by industry, employment size, geographic area, and major occupational group. As an example of the benchmarking process, 40 private industry units, 10 local government units, and 5 state government units in the service sector were selected from the ORS sampling frame. These units consist of establishments employing 200,000 private industry workers, 30,000 local government workers, and 10,000 state government workers. If, by the time of survey processing, the private service sector experienced an employment increase of 10,000 workers (5 percent) and there is no increase in employment in the service sectors of state and local government, then the sample would underrepresent current employment in the private industry service sector in the absence of benchmarking. In this example, the ORS program would adjust the sample weights of the 40 service sector firms in private industry to ensure that the number of workers in establishments in the sampling frame rises to 210,000. The ownership employment counts for the private industry service sector would then reflect the current proportions of 84 percent for private industry, 12 percent for local government, and 4 percent for state government employment. WeightingAn establishment is considered responding if it provided information for at least one sampled job. Similarly, a nonresponding establishment is one that is unable or unwilling to provide information for at least one sampled job. If the respondent for an establishment refuses to participate, then the associated establishment is considered nonresponding. The ORS program adjusts weights for establishment nonresponse by redistributing the weights of nonresponding establishments to similar establishments. The ORS program groups similar respondents into cells that are defined by characteristics such as the industry, size class, and geographic area of the establishment. For example, if the nonresponding establishment was in the manufacturing industry and had an employment of 350 workers, the ORS program would adjust the weights of responding manufacturing establishments with 100–499 workers during estimation. Applied at the establishment level, this adjustment is a nonresponse adjustment factor (NRAF), and it is calculated using the following formula:
where ∑A = weighted employment of all usable establishments in the nonresponse cell, and ∑B = weighted employment of all viable but not usable establishments in the nonresponse cell. If there are no responding establishments to reweight within the industry or employment size group, then additional responding units from similar geographic areas are considered. Establishments no longer in operation or out of the scope of the survey and establishments with no workers within the scope of the survey are considered unviable and excluded from survey estimates. The ORS program may also adjust weights for sampled job nonresponse, which is when an establishment does not provide any occupational requirements data for a given sampled job. The ORS program addresses sampled job nonresponse during the interview with an adjustment that redistributes the weights of nonresponding sampled jobs to responding sampled jobs in the same occupational group, ownership, industry, size class, and geographic area. In addition to the job nonresponse adjustment factor, final occupational weights consider the sampling process used to select jobs, the establishment weight, and overall employment. The design section provides more information on the job selection process. The ORS program applies additional adjustment factors to special situations that may have occurred during data collection. For example, when a sample unit is one of two establishments owned by a given company and the respondent provides data for both locations combined instead of data for the sampled unit, the ORS program adjusts the weight of the sampled unit to reflect the employment data for the sampled unit. ImputationItem nonresponse occurs when an establishment responds to the survey but is unable or unwilling to provide some of the occupational requirements for a given sampled job. Item nonresponse is addressed through item imputation in certain situations. Item imputation replaces missing values for an item or items with values derived from sampled jobs within similar establishments with similar worker characteristics that have a value for the item. For ORS estimates, items with missing values are imputed within groups of ORS job requirements that are related. For example, one ORS group refers to categorical variables only and includes such requirements as vision and driving. Within the group, the ORS imputes values by a process that matches sampled jobs using occupational information from similar occupations in similar establishments. For estimates that are calculated from multiple values, such as strength and specific vocational preparation (SVP), missing component values are imputed to calculate these estimates. For more information, see estimation within the survey methodology category of the research section of the ORS website. Reliability of ORS estimatesTo assist users in confirming the reliability of ORS estimates, ORS publishes standard errors. Standard errors provide users with a measure of the precision of an estimate to ensure that the measure is within an acceptable range for their intended purpose. The standard errors are calculated from collected and imputed data. Examples on how to build confidence intervals using standard errors are included in the standard error section of the ORS website. The ORS derives estimates from sampled jobs within responding establishments. Two types of errors are possible in an estimate based on a sample survey: sampling and nonsampling errors. Sampling errors occur because the sample makes up only a part of the population it represents. The sample used for the survey is one of several possible samples that could have been selected under the sample design, each producing its own estimate. A measure of the variation among sample estimates is the standard error. Nonsampling errors are data errors that stem from any source other than sampling error, such as data collection errors and data processing errors. Standard errors can be used to measure the precision with which an estimate from a particular sample approximates the expected result of all possible samples. The chances are about 68 out of 100 that an estimate from the survey differs from a complete population figure by less than the standard error. The chances are about 90 out of 100 that this difference is less than 1.6 times the standard error. Statements of comparison appearing in ORS publications are significant at a level of 1.6 standard errors or better. This means that, for differences cited, the estimated difference is more than 1.6 times the standard error of the difference. The ORS uses balanced repeated replication (BRR) to estimate the standard error. The procedure for BRR starts by first partitioning the sample into variance strata composed of a single sampling stratum or clusters of sampling strata, and then splitting the sample units in each variance stratum evenly into two variance primary sampling units (PSUs). Next, the ORS program chooses half-samples so that each contains exactly one variance PSU from each variance stratum. Choices are not random but are designed to yield a balanced collection of half-samples. By using half-samples, the ORS program can compute a replicate estimate with the same formula for the regular or full-sample estimate, except that the final weights are adjusted. If a unit is in the half-sample, its weight is multiplied by (2 – k); if not, its weight is multiplied by k. For all ORS publications, k = 0.5, so the multipliers are 1.5 and 0.5. The BRR estimate of the standard error with R half-samples is
where the summation is over all replicates of half-samples r = 1,...,R,
Quality assuranceThe ORS program uses a variety of quality assurance programs to mitigate collection and processing errors by using data collection reinterviews, observed interviews, computer edits of the data, and systematic professional review of the data. These quality assurance programs also serve as a training device to provide feedback to field economists on errors and the sources of errors that can be remedied by improved collection instructions or computer-processing edits. Field economists receive extensive training to maintain high standards in data collection. Once estimates of occupational requirements are produced, the estimates are validated. The focus of the validation is to compare the estimates with expectations for them. This process assesses the reliability of the estimates, as well as ensures that weighting, benchmarking, and imputation are working as expected. Although not a time series, the validation process accounts for economic events each year that might have an impact on collection and estimates. Expectations are based on prior year estimates and similar estimates from other sources of data, such as the Occupational Information Network (O*NET). The ORS program investigates estimates that deviate from their expectations to ensure that the underlying data are consistent with ORS collection procedures and that the calculation is consistent with ORS statistical procedures. If it is determined that the data misrepresent expectations or collection procedures, the underlying data will be removed from estimation or the estimate will not be published. Before publishing any estimate, the ORS program reviews the estimate to make sure that it meets specified statistical reliability and confidentiality requirements. For more information, see the data review and estimation tabs on the research section of the ORS website. Estimates that are consistent with these procedures are designated as fit for use and released in U.S. Bureau of Labor Statistics (BLS) publications.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
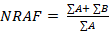
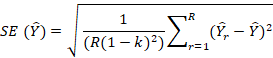
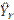 is the rth replicate estimate, and
is the rth replicate estimate, and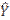 is the full-sample estimate.
is the full-sample estimate.