
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
The JOLTS sample of 21,000 establishments does not directly support the production of sample based state estimates. However, state estimates have been produced by combining the available sample with model-based estimates. As of October 2021, JOLTS state-level estimates will be made available in an official monthly release approximately two weeks after the JOLTS national release. BLS invites data users to comment on both the methodology used to produce these estimates and on the usefulness of these data.
These estimates consist of four major estimating models; the Composite Regional model (an unpublished intermediate model), the Synthetic model (an unpublished intermediate model), the Composite Synthetic model (published historical series through the most current benchmark year), and the Extended Composite Synthetic model (published current-year monthly series). The Composite Regional model uses JOLTS microdata, JOLTS regional published estimates, and Current Employment Statistics (CES) employment data. The Composite Synthetic model uses JOLTS microdata and Synthetic model estimates derived from monthly employment changes in microdata from the Quarterly Census of Employment and Wages (QCEW), and JOLTS published regional data. The Extended Composite Synthetic extends the Composite Synthetic estimates by ratio-adjusting the Composite Synthetic by the ratio of the current Composite Regional model estimate to the Composite Regional model estimate from one year ago.
The Extended Composite Synthetic model (and its major component—the Composite Regional model) is used to extend the Composite Synthetic estimates because all of the inputs required by this model are available at the time monthly estimate are produced. In contrast, the Composite Synthetic model (and its major component—the Synthetic model) can only be produced when the latest QCEW data are available. The plan is to use Extended Composite Synthetic model estimates to extend the Composite Synthetic model estimates during the annual JOLTS re-tabulation process. The extension of the Composite Synthetic model using current data-based Composite Regional model estimates will ensure that the Composite Synthetic model estimates reflect current economic trends.
The following outlines each model in a non-technical summary format. Each model is summarized separately, and answers the following:
The Composite Regional approach calculates state-level JOLTS estimates from JOLTS microdata using sample weights, and the adjustments for non-response (NRAF). The Composite Regional estimate is then benchmarked to CES state-supersector employment to produce state-supersector estimates. The JOLTS sample, by itself, cannot ensure a reasonably sized sample for each state-supersector cell. The small JOLTS sample results in quite a number of state-supersector cells that lack enough data to produce a reasonable estimate. To overcome this issue, the state-level estimates derived directly from the JOLTS sample are augmented using JOLTS regional estimates when the number of respondents is low (that is, less than 30). This approach is known as a composite estimate which leverages the small JOLTS sample to the greatest extent possible and supplements that with a model-based estimate. Previous research has found that regional industry estimates are a good proxy at finer levels of geographical detail. That is, one can make a good prediction of JOLTS estimates at the regional-level using only national industry-level JOLTS rates. The assumption in this approach is that one can make a good prediction of JOLTS estimates at the state-level using only regional industry-level JOLTS rates.
In this approach, the JOLTS microdata-based estimate is used, without model augmentation, in all state-supersector cells that have 30 or more respondents. The JOLTS regional estimate will be used, without a sample-based component, in all state-supersector cells that have fewer than five respondents. In all state-supersector cells with 5–30 respondents an estimate is calculated that is a composition of a weighted estimate of the microdata-based estimate and a weighted estimate of the JOLTS regional estimate. The weight assigned to the JOLTS data in those cells is proportional the number of JOLTS respondents in the cell (weight=n∕30, where n is the number of respondents).
These estimates are based upon a model. BLS constructed a methodology to produce error measures of estimates, which will be updated annually in July.
The Synthetic model differs fundamentally from the Composite Regional model. The Synthetic approach does not use JOLTS microdata but rather it uses data from the QCEW that have been linked longitudinally (Longitudinal Database—LDB), the QCEW-LDB. The Synthetic model attempts to convert QCEW-LDB monthly employment change microdata into JOLTS job openings, hires, quits, layoffs and discharges, and total separations data.
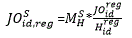
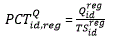
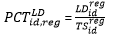

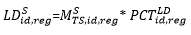
These estimates are based upon a model. BLS constructed a methodology to produce error measures of estimates, which will be updated annually in July.
The Composite Synthetic model is nearly identical to the Composite Regional model. The primary difference is the use of the Synthetic model estimates (described in the first section) rather than JOLTS published regional estimates when there is an insufficient amount of JOLTS microdata to produce a state-supersector estimate.
Just like the Composite Regional approach, the JOLTS microdata-based estimate is used in all state-supersector cells that have 30 or more respondents. However, in contrast to the Composite Regional approach, the Composite Synthetic approach uses the Synthetic estimate in all state-supersector cells that have fewer than five respondents. In all state-supersector cells with 5–30 respondents an estimate is calculated that is a composition of a weighted estimate of the microdata-based estimate and a weighted estimate of the Synthetic estimate. The weight assigned to the JOLTS data in those cells is proportional the number of JOLTS respondents in the cell (weight=n∕30, where n is the number of respondents).
The Composite Synthetic supersector estimates are summed across state-supersectors to the nonfarm level.
These estimates are based upon a model. BLS constructed a methodology to produce error measures of estimates, which will be updated annually in July.
The Extended Composite Synthetic model is designed to project the Composite Synthetic forward until QCEW-LDB data are available to produce Composite Synthetic estimates. The Composite Synthetic estimates are extended using the ratio of the current Composite Regional state industry estimate to the Composite Regional state industry estimate from one year ago.
This approach ensures that the Extended Composite Synthetic state estimates reflect current JOLTS regional and industry-level economic conditions. The Extended Composite Synthetic estimates reflects current JOLTS state economic conditions to the extent that sufficient JOLTS microdata are available.
The Composite Synthetic model estimates are produced at a lag since QCEW-LDB data are only available at a 6–9 month lag relative to JOLTS data. The Composite Regional model estimates, in contrast, are not produced at a lag and are available concurrent with JOLTS data. Therefore, Composite Synthetic estimates can be extended by ratio-adjusting the Composite Synthetic estimates by the ratio of current Composite Regional estimates to the Composite Regional estimates from one year ago at the state-industry-level as follows:
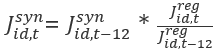
Where
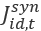 is the Extended Composite Synthetic state industry estimate for month t
is the Extended Composite Synthetic state industry estimate for month t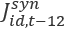 is the Composite Synthetic state industry estimate for month t-12 (one year ago)
is the Composite Synthetic state industry estimate for month t-12 (one year ago)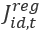 is the Composite Regional state industry estimate for month t
is the Composite Regional state industry estimate for month t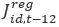 is the Composite Regional state industry estimate for month t-12 (one year ago)
is the Composite Regional state industry estimate for month t-12 (one year ago)State-level estimates are produced by summing the Extended Composite Synthetic estimates over industry.
These estimates are based upon a model. BLS constructed a methodology to produce error measures of estimates, which will be updated annually in July.
Winsorization is a process used to safeguard against extreme values or outliers that potentially could unduly impact a forecasted estimate. The technique for JOLTS state estimates involves identifying monthly outliers by state and data element and replacing them with winsorized values. Although unusually high values are rare, having safeguards against extreme values will lessen the impact of these anomalies and reduce the volatility in JOLTS State estimates.
The JOLTS State Estimates are based on a composite model of QCEW data and JOLTS reported data. However, while current JOLTS reported data are available at the time of production, current QCEW data are not. Consequently, JOLTS State estimates are forecasted using the previous year’s QCEW estimate and JOLTS regional rates. By definition, the year-ago QCEW estimate is multiplied by the ratio of the current Regional estimate to the year-ago Regional estimate at the State/CES ID level:
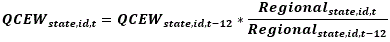
The ratio of the current Regional estimate to the year-ago Regional estimate at the State/CES ID level 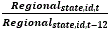 is winsorized. The winsorization cutoffs are the historical 99th percentile of regional ratios for each variable (job openings, hires, quits, layoffs and discharges, and other separations). Even though other separations are not published for state estimates it is still identified in the winsorization process as it is one of the components to total separations.
is winsorized. The winsorization cutoffs are the historical 99th percentile of regional ratios for each variable (job openings, hires, quits, layoffs and discharges, and other separations). Even though other separations are not published for state estimates it is still identified in the winsorization process as it is one of the components to total separations.
Please visit the state-level estimation section of JOLTS Handbook of Methods for detailed information on the JOLTS state methodology.
Most series published by the Job Opening and Labor Turnover Survey (JOLTS) program have a regularly recurring seasonal movement that can be measured from past data. Seasonal adjustment eliminates the component of the change attributable to the normal seasonal variation and makes it possible to observe the cyclical and other nonseasonal component movements in the series. Seasonally adjusted series are published monthly for JOLTS estimates. The JOLTS program uses X-13-ARIMA-SEATS software developed by the U.S. Census Bureau to seasonally adjust the monthly estimates. The X-13-ARIMA-SEATS software is available on the U.S. Census Bureau website. The JOLTS program employs a concurrent seasonal adjustment methodology to seasonally adjust its estimates. Under concurrent methodology, new seasonal factors are calculated each month using all relevant data up to and including the current month period.
All controllable variables remain fixed during the year. For example, the ARIMA model, outliers, transformation specification, and historical data are held constant. Once a year, as part of the annual JOLTS benchmark procedure, all seasonal adjustment specifications are reviewed for each series. Any changes are implemented and kept constant until the next annual benchmark. Also during the annual benchmark, estimates for the 5 most recent years are readjusted using the new specifications. Estimates are only revised back for a 5-year period.
The model specifications provide the mode (additive or multiplicative) selected for each JOLTS series by state. Depending on the relationship between the original series and each of the components, the mode of seasonal adjustment may be additive or multiplicative. Formal tests are conducted to determine the appropriate mode of adjustment.
The multiplicative mode assumes that the magnitude of the seasonal pattern is proportional to the level, which implies that the size of the seasonal fluctuations increases and decreases with the level of the series. With this mode, the monthly seasonal factors are ratios, with all positive values centered around one. The seasonally adjusted values are computed by dividing each month's original value by the corresponding seasonal factor.
In contrast, the additive mode assumes that the magnitude of the seasonal pattern is independent of the level of the series. In this case, the seasonal factors represent positive or negative deviations from the original series and are centered around zero. The seasonally adjusted values are computed by subtracting the corresponding seasonal factor from each month's original value.
A raking procedure is used to ensure that the sum of the seasonally adjusted state series is consistent with the published seasonally adjusted total at the regional levels. The raking procedure begins by seasonally adjusting the regional and state level series independently. The seasonally adjusted state series are summed to the regional levels to get the regional totals. Ratios of seasonally adjusted state-to-regional levels are calculated. The regional totals summarized from the seasonally adjusted state series are subtracted from the official regional seasonally adjusted estimates to determine the amount that must be raked. The total amount that must be raked is multiplied by the ratios to determine what percentage of the raked amount should be applied to each state. Once the seasonally adjusted state series receive their proportional amount of the raked values, the two groups are aggregated again to regional totals. At this point their sum should be equal to the official regional seasonally adjusted estimate.
The JOLTS state estimates sample allocation table below provides a snapshot of the sample used to produce December 2023 and December 2024 state estimates. Sample are utilized in both components of the model. The sample component table includes JOLTS state respondent and sample data. The model component includes JOLTS regional-level sample and respondent data, CES state respondent data, and QCEW establishment counts.
| State | FIPS Code | Region | JOLTS State Sample [1] | JOLTS State Respondents[2] | JOLTS Regional-level Sample[1] | JOLTS Regional-level Respondents[3] | QCEW Establishments[4] | CES State[5] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023 | 2024 | 2023 | 2024 | 2023 | 2024 | 2023 | 2024 | 2023 | 2024 | 2023 | 2024 | |||
|
Alabama |
1 | South | 337 | 329 | 101 | 98 | 8,721 | 8,599 | 2,156 | 2,183 | 155,553 | 158,900 | 12,950 | 13,060 |
|
Alaska |
2 | West | 88 | 87 | 25 | 28 | 6,819 | 6,733 | 1,485 | 1,581 | 24,882 | 24,987 | 2,260 | 2,250 |
|
Arizona |
4 | West | 586 | 589 | 136 | 144 | 6,819 | 6,733 | 1,485 | 1,581 | 217,668 | 217,387 | 11,480 | 12,520 |
|
Arkansas |
5 | South | 180 | 173 | 52 | 54 | 8,721 | 8,599 | 2,156 | 2,183 | 100,957 | 103,802 | 6,530 | 6,580 |
|
California |
6 | West | 3,304 | 3,208 | 647 | 654 | 6,819 | 6,733 | 1,485 | 1,581 | 1,789,669 | 1,900,725 | 66,980 | 67,560 |
|
Colorado |
8 | West | 614 | 593 | 150 | 172 | 6,819 | 6,733 | 1,485 | 1,581 | 258,772 | 235,253 | 9,500 | 9,740 |
|
Connecticut |
9 | Northeast | 324 | 341 | 81 | 100 | 5,995 | 6,040 | 1,447 | 1,550 | 138,737 | 145,568 | 6,710 | 6,560 |
|
Delaware |
10 | South | 72 | 64 | 21 | 21 | 8,721 | 8,599 | 2,156 | 2,183 | 41,555 | 43,367 | 1,970 | 1,970 |
|
District of Columbia |
11 | South | 124 | 113 | 25 | 21 | 8,721 | 8,599 | 2,156 | 2,183 | 50,604 | 50,093 | 2,070 | 2,070 |
|
Florida |
12 | South | 1,529 | 1,528 | 320 | 332 | 8,721 | 8,599 | 2,156 | 2,183 | 867,805 | 885,078 | 40,110 | 38,580 |
|
Georgia |
13 | South | 719 | 711 | 186 | 192 | 8,721 | 8,599 | 2,156 | 2,183 | 371,262 | 384,071 | 23,860 | 24,910 |
|
Hawaii |
15 | West | 106 | 102 | 26 | 19 | 6,819 | 6,733 | 1,485 | 1,581 | 55,102 | 58,036 | 2,390 | 2,220 |
|
Idaho |
16 | West | 175 | 176 | 46 | 54 | 6,819 | 6,733 | 1,485 | 1,581 | 93,108 | 100,258 | 4,090 | 4,270 |
|
Illinois |
17 | Midwest | 1,208 | 1,255 | 282 | 308 | 6,249 | 6,343 | 1,622 | 1,679 | 390,546 | 391,565 | 20,050 | 19,920 |
|
Indiana |
18 | Midwest | 581 | 586 | 157 | 155 | 6,249 | 6,343 | 1,622 | 1,679 | 187,371 | 190,190 | 11,350 | 11,410 |
|
Iowa |
19 | Midwest | 302 | 284 | 76 | 85 | 6,249 | 6,343 | 1,622 | 1,679 | 109,534 | 111,148 | 9,000 | 8,760 |
|
Kansas |
20 | Midwest | 310 | 330 | 108 | 97 | 6,249 | 6,343 | 1,622 | 1,679 | 98,964 | 91,845 | 6,540 | 6,830 |
|
Kentucky |
21 | South | 294 | 267 | 87 | 72 | 8,721 | 8,599 | 2,156 | 2,183 | 149,862 | 154,999 | 8,110 | 8,030 |
|
Louisiana |
22 | South | 301 | 293 | 77 | 81 | 8,721 | 8,599 | 2,156 | 2,183 | 145,308 | 147,508 | 8,930 | 9,580 |
|
Maine |
23 | Northeast | 165 | 150 | 61 | 49 | 5,995 | 6,040 | 1,447 | 1,550 | 63,030 | 64,252 | 4,680 | 4,780 |
|
Maryland |
24 | South | 382 | 384 | 84 | 92 | 8,721 | 8,599 | 2,156 | 2,183 | 188,837 | 190,426 | 8,830 | 9,450 |
|
Massachusetts |
25 | Northeast | 780 | 777 | 171 | 191 | 5,995 | 6,040 | 1,447 | 1,550 | 291,755 | 286,373 | 12,110 | 11,750 |
|
Michigan |
26 | Midwest | 862 | 888 | 216 | 218 | 6,249 | 6,343 | 1,622 | 1,679 | 323,518 | 299,061 | 14,710 | 14,710 |
|
Minnesota |
27 | Midwest | 517 | 525 | 135 | 147 | 6,249 | 6,343 | 1,622 | 1,679 | 208,727 | 214,600 | 9,070 | 8,960 |
|
Mississippi |
28 | South | 193 | 192 | 67 | 65 | 8,721 | 8,599 | 2,156 | 2,183 | 85,664 | 87,224 | 6,760 | 6,650 |
|
Missouri |
29 | Midwest | 602 | 622 | 150 | 154 | 6,249 | 6,343 | 1,622 | 1,679 | 250,951 | 249,924 | 15,650 | 15,070 |
|
Montana |
30 | West | 121 | 137 | 28 | 31 | 6,819 | 6,733 | 1,485 | 1,581 | 66,809 | 64,723 | 3,600 | 3,510 |
|
Nebraska |
31 | Midwest | 196 | 203 | 61 | 56 | 6,249 | 6,343 | 1,622 | 1,679 | 76,406 | 77,800 | 4,840 | 4,900 |
|
Nevada |
32 | West | 231 | 231 | 46 | 53 | 6,819 | 6,733 | 1,485 | 1,581 | 108,029 | 107,909 | 3,590 | 3,650 |
|
New Hampshire |
33 | Northeast | 174 | 174 | 48 | 55 | 5,995 | 6,040 | 1,447 | 1,550 | 65,695 | 67,075 | 4,120 | 4,200 |
|
New Jersey |
34 | Northeast | 971 | 980 | 218 | 257 | 5,995 | 6,040 | 1,447 | 1,550 | 333,466 | 338,666 | 17,580 | 17,200 |
|
New Mexico |
35 | West | 208 | 210 | 59 | 57 | 6,819 | 6,733 | 1,485 | 1,581 | 68,298 | 68,475 | 6,360 | 6,360 |
|
New York |
36 | Northeast | 2,033 | 2,077 | 472 | 481 | 5,995 | 6,040 | 1,447 | 1,550 | 680,024 | 691,008 | 41,010 | 38,830 |
|
North Carolina |
37 | South | 734 | 748 | 202 | 208 | 8,721 | 8,599 | 2,156 | 2,183 | 370,848 | 373,501 | 19,530 | 19,730 |
|
North Dakota |
38 | Midwest | 151 | 153 | 44 | 45 | 6,249 | 6,343 | 1,622 | 1,679 | 35,169 | 35,820 | 2,600 | 2,720 |
|
Ohio |
39 | Midwest | 964 | 965 | 239 | 265 | 6,249 | 6,343 | 1,622 | 1,679 | 333,355 | 345,616 | 23,960 | 23,970 |
|
Oklahoma |
40 | South | 282 | 267 | 75 | 83 | 8,721 | 8,599 | 2,156 | 2,183 | 128,593 | 126,015 | 8,290 | 8,930 |
|
Oregon |
41 | West | 323 | 327 | 65 | 91 | 6,819 | 6,733 | 1,485 | 1,581 | 192,678 | 180,576 | 10,760 | 11,850 |
|
Pennsylvania |
42 | Northeast | 1,348 | 1,334 | 342 | 356 | 5,995 | 6,040 | 1,447 | 1,550 | 391,817 | 394,471 | 21,770 | 21,430 |
|
Rhode Island |
44 | Northeast | 118 | 132 | 28 | 35 | 5,995 | 6,040 | 1,447 | 1,550 | 47,887 | 48,339 | 1,770 | 1,820 |
|
South Carolina |
45 | South | 369 | 371 | 109 | 94 | 8,721 | 8,599 | 2,156 | 2,183 | 175,903 | 190,497 | 10,560 | 10,040 |
|
South Dakota |
46 | Midwest | 99 | 86 | 35 | 31 | 6,249 | 6,343 | 1,622 | 1,679 | 39,806 | 40,503 | 2,380 | 2,450 |
|
Tennessee |
47 | South | 450 | 443 | 131 | 130 | 8,721 | 8,599 | 2,156 | 2,183 | 216,347 | 225,321 | 12,560 | 12,920 |
|
Texas |
48 | South | 2,061 | 2,014 | 447 | 463 | 8,721 | 8,599 | 2,156 | 2,183 | 824,511 | 836,955 | 49,210 | 49,820 |
|
Utah |
49 | West | 387 | 368 | 99 | 98 | 6,819 | 6,733 | 1,485 | 1,581 | 137,894 | 141,514 | 7,630 | 7,550 |
|
Vermont |
50 | Northeast | 82 | 75 | 26 | 26 | 5,995 | 6,040 | 1,447 | 1,550 | 32,144 | 33,195 | 2,230 | 2,180 |
|
Virginia |
51 | South | 567 | 571 | 133 | 134 | 8,721 | 8,599 | 2,156 | 2,183 | 310,209 | 314,526 | 17,890 | 17,940 |
|
Washington |
53 | West | 588 | 618 | 135 | 154 | 6,819 | 6,733 | 1,485 | 1,581 | 234,753 | 233,366 | 11,500 | 11,540 |
|
West Virginia |
54 | South | 127 | 131 | 39 | 43 | 8,721 | 8,599 | 2,156 | 2,183 | 58,461 | 60,527 | 5,500 | 5,800 |
|
Wisconsin |
55 | Midwest | 457 | 446 | 119 | 118 | 6,249 | 6,343 | 1,622 | 1,679 | 205,133 | 208,268 | 10,800 | 11,010 |
|
Wyoming |
56 | West | 88 | 87 | 23 | 26 | 6,819 | 6,733 | 1,485 | 1,581 | 30,241 | 30,557 | 2,620 | 2,540 |
|
All states and D.C. |
27,784 | 27,715 | 6,710 | 6,993 | 27,784 | 364,188 | 88,444 | 91,762 | 11,824,217 | 12,021,863 | 629,350 | 631,080 | ||
|
Footnotes: 1) JOLTS State and Regional - Level Sample 2) JOLTS Sample Units used in Sample Component of the Composite & Extended Composite Models 3) JOLTS Sample Units used in Model Component of the Composite & Extended Composite; the Total is the sum of the four regions 4) QCEW Establishments used in the Model Component of the Synthetic and Composite Synthetic Model 5) CES UI Sample Units used in Model Component of the Composite Synthetic & Extended Composite Models |
||||||||||||||
JOLTS state estimates are subject to both sampling and nonsampling error. Sampling error occurs when a sample is surveyed rather than the entire population. There is a chance that the sample estimates may differ from the true population values they represent. The difference, or sampling error, varies depending on the particular sample selected. This variability is measured by the standard error of the estimate. BLS analysis is generally conducted at the 90-percent level of confidence. That means that there is a 90-percent chance, or level of confidence, that an estimate based on a sample will differ by no more than 1.6 standard errors from the true population value because of sampling error.
The JOLTS state estimates also are affected by nonsampling error. Nonsampling error can occur for many reasons including: the failure to include a segment of the population; the inability to obtain data from all units in the sample; the inability or unwillingness of respondents to provide data on a timely basis; mistakes made by respondents; errors made in the collection or processing of the data; and errors from the employment benchmark data used in estimation.
The JOLTS State variance estimates account for both sampling error and the error attributable to modeling. A small area domain model uses a Bayesian model to develop estimates of JOLTS State variance. The small area model uses QCEW-based JOLTS synthetic model data to generate a Bayesian prior distribution, then updates the prior distribution using JOLTS microdata and sample-based variance estimates at the State and US Census Regional level to generate a Bayesian posterior distribution. Once the Bayesian posterior distribution has been generated, an estimate of JOLTS State variance estimates is made by drawing 2,500 estimates from the Bayesian posterior distribution. This Bayesian approach thus indirectly accounts for sampling error and directly for model error. The median standard errors table by state is available on the JOLTS Median Standard Errors page. The error measures will be updated annually in July.
Last Modified Date: July 23, 2025