
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
Employee Benefits is a product of the National Compensation Survey (NCS), which collects data on the incidence and provisions of selected employee benefit plans. The calculation details for Employee Benefits are covered in this section.
The Employee Benefits program collects and publishes data annually on the incidence of employer-provided benefits and on the key provisions (terms) of employee benefit plans, for civilian workers, workers in private industry, and state and local government workers. Exhibit 1 lists the types of published benefits.
Retirement | Defined benefit and defined contribution plans, retirement combinations, and other retirement plans |
|---|---|
Healthcare | Preventive and protective medical, dental, vision, and prescription drug coverage to employees and their families |
Life insurance | Lump-sum payment to a designated beneficiary or beneficiaries of a deceased employee |
Disability | Protection against loss of income due to a nonoccupational illness or injury (short-term and long-term) |
Leave | Paid and unpaid leave benefits to employees (sick leave, jury duty, personal leave, holidays, vacations, and paid and unpaid family leave) |
Other Benefits | Quality of life, financial, and section 125 cafeteria benefits |
Source: U.S. Bureau of Labor Statistics. | |
In addition, the Employee Benefits program publishes data on detailed provisions of coverage in two major benefit areas: health insurance and retirement plans. Health data include medical plan provisions, such as deductibles, coinsurance, and out-of-pocket maximums, as well as details of dental, vision, and prescription drug benefits. Provisions of defined benefit and defined contribution retirement plans, such as eligibility requirements and benefit formulas, are also published. While the Incidence and Provisions publication uses updates schedules in its calculations, detailed provision estimates are produced based on the initiation year (the first year of participation in the NCS for the sampled establishment) of each sample group using data from Summary Plan Descriptions (SPD), plan summary sheets, and Summary of Benefits and Coverage (SBC) documents.
The formula for the percentage of employees with access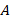 to a benefit area, such as life insurance, for domain
to a benefit area, such as life insurance, for domain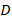 is
is
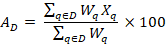
where
is the domain of interest;
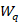 is the final weight for quote
is the final weight for quote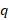 , calculated as the product of the number of workers represented by the quote at sampling, unit and quote nonresponse factors, benchmark factors, and any additional adjustment factors;
, calculated as the product of the number of workers represented by the quote at sampling, unit and quote nonresponse factors, benchmark factors, and any additional adjustment factors;
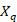 equals 1 if the worker in quote has access to the benefit being estimated; and
equals 1 if the worker in quote has access to the benefit being estimated; and
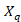 equals 0 otherwise.
equals 0 otherwise.
The formula for the percentage of employees participating in a benefit area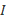 , such as medical care, for domain is
, such as medical care, for domain is
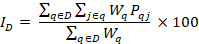
where
is the domain of interest;
is the final quote weight for quote, calculated as described previously; and
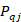 is the percentage of workers in quote who are participating in benefit-area plan
is the percentage of workers in quote who are participating in benefit-area plan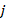 .
.
Other estimates of incidence, such as the percentage of participants in a benefit area or in a subset of a benefit area, can be computed in a similar manner, such that the base includes only those workers who participate in the benefit-area plans. For example, to calculate the percentage of medical insurance participants in fee-for-service plans in domain, a ratio is calculated such that the denominator is the same as the numerator in the previous formula and the numerator is of the same form as well, except that the summation is restricted to those participants in fee-for-service plans.
This is the formula for the percent of workers with access to a benefit area who participate in the benefit. The numerator represents the multiplication of the sum of the final benchmarked quote weights by the participation rate for only those plans in the quotes that meet the specific conditions defined by the quote conditions and additional plan (numerator) restrictions. The denominator is calculated from the final benchmarked quote weights of those quotes that have access to a benefit area defined by the quote conditions and base (denominator) conditions. Multiplying the final quotient by 100 yields a percent. The take-up rate is defined as
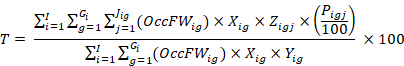
where
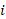 is an establishment,
is an establishment,
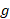 is an occupation within establishment,
is an occupation within establishment,
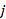 is a plan in occupation in establishment,
is a plan in occupation in establishment,
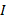 is the total number of establishments,
is the total number of establishments,
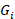 is the total number of quotes in establishment,
is the total number of quotes in establishment,
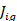 is thetotal number of plans in quote in establishment,
is thetotal number of plans in quote in establishment,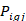 is the percent of workers in occupation and establishment, participating in plan,
is the percent of workers in occupation and establishment, participating in plan,
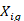 equals 1 if quote
equals 1 if quote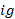 meets the condition set in the quote (row) condition and equals 0 otherwise,
meets the condition set in the quote (row) condition and equals 0 otherwise,
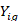 equals 1 if quote meets the access condition set in the base (denominator) plan condition and equals 0 otherwise,
equals 1 if quote meets the access condition set in the base (denominator) plan condition and equals 0 otherwise,
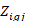 equals 1 if plan
equals 1 if plan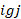 meets the condition set in the additional (numerator) plan condition and equals 0 otherwise,
meets the condition set in the additional (numerator) plan condition and equals 0 otherwise,
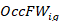 is the final benchmarked quote weight for occupation in establishment, and
is the final benchmarked quote weight for occupation in establishment, and
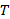 equals the take-up rate.
equals the take-up rate.
The formula for the average flat monthly employee contribution for medical insurance for domain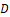 is
is
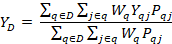
where
is the domain of interest;
is the final quote weight for quote, calculated as described previously;
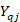 is the average monthly employee contribution to planby workers in quote; and
is the average monthly employee contribution to planby workers in quote; and
is the percentage of workers in quote who are participating in plan.
Other means, such as the average annual deductible for medical insurance, can be calculated by a similar formula. In all cases, the averages include only those workers with the provision in question.
Percentiles of benefit provisions are calculated with data only from those workers in plans that include the provision in question. Percentile data are used to describe the distribution of a numeric value, such as a median annual deductible of $400.00 and the value $600.00 at the 90th percentile. The following percentiles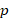 are calculated: 10, 25, 50 (median), 75, and 90.
are calculated: 10, 25, 50 (median), 75, and 90.
The th percentile is the value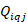 , where the plan value of a quantity is for a specific benefit or a subset of a benefit area, such thatthe weighted plan employment (
, where the plan value of a quantity is for a specific benefit or a subset of a benefit area, such thatthe weighted plan employment (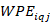 ) across plans with a value less than
) across plans with a value less than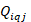 is less than percent of the total weighted plan employment andthe weighted plan employment () across plans with a value more than is less than (
is less than percent of the total weighted plan employment andthe weighted plan employment () across plans with a value more than is less than (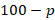 ) percent of the total weighted plan employment.
) percent of the total weighted plan employment.
It is possible that there are no specific plan records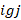 for which both of these properties hold. This occurs when there exists a plan for which the
for which both of these properties hold. This occurs when there exists a plan for which the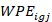 of records whose value is less than
of records whose value is less than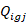 equals percent of the total weighted plan employment. In this situation, theth percentile is the average ofand the value on the record with the next lowest value. Thevalues must be sorted in ascending order.
equals percent of the total weighted plan employment. In this situation, theth percentile is the average ofand the value on the record with the next lowest value. Thevalues must be sorted in ascending order.
The weighted count of workers participating in plans available to them in the sampled occupation and establishment is calculated by multiplying the final benchmarked quote weight by the participation rate for only those plans in the quote that meet the specific conditions defined by the quote condition and the plan conditions. The weighted count of workers is defined as

where
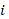 is an establishment,
is an establishment,
is an occupation within establishment,
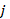 is a plan in occupation in establishment,
is a plan in occupation in establishment,
is the percent of workers in occupation and establishment, participating in plan,
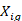 equals 1 if quote meets the condition set in the quote condition and equals 0 otherwise,
equals 1 if quote meets the condition set in the quote condition and equals 0 otherwise,
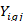 equals 1 if plan meets the condition set in the base (denominator) plan condition and equals 0 otherwise,
equals 1 if plan meets the condition set in the base (denominator) plan condition and equals 0 otherwise,
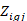 equals 1 if plan meets the condition set in the additional (numerator) plan condition and equals 0 otherwise,
equals 1 if plan meets the condition set in the additional (numerator) plan condition and equals 0 otherwise,
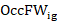 is the final benchmarked quote weight for occupation in establishment,
is the final benchmarked quote weight for occupation in establishment,
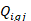 is the plan value of a quantity for a specific benefit or subset of a benefit area,
is the plan value of a quantity for a specific benefit or subset of a benefit area,
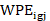 is the weighted plan employment of record, and
is the weighted plan employment of record, and
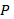 is the percentile.
is the percentile.
Participation in the NCS is voluntary; therefore, a company official may refuse to participate in the initial survey or may be unwilling or unable to update previously provided data for one or more occupations during subsequent contact. In addition, some establishments selected from the sample frame may be out of the scope of the survey or may have gone out of business. To address the problems of nonresponse and missing data, the NCS adjusts the weights of the remaining establishments and imputes missing values (for example, fills in missing values with plausible values). To ensure that published estimates are representative of compensation in the civilian, private industry, and state and local government sectors, weight adjustments and imputation are made in accordance with the following steps:
Step 1.Unit nonresponse adjustment. An establishment is considered responding if it provided information on at least one usable occupation. A selected occupation is classified as usable if the following data are present: occupational attributes (full-time or part-time schedule, union or nonunion status, and time or incentive type of pay), work schedule, and wage data. Wages account for approximately 70 percent of compensation; therefore, if wage data are not available, other data from the establishment cannot be used in calculating estimates. Without the wage data, it is not possible to create benefit-cost estimates because many benefits, such as paid leave, for example, are linked to wages.
An establishment is considered nonresponding if it refused to participate in the survey or did not provide wages and salaries, occupational classification, worker attributes, and work schedule data for any selected occupation. Establishment nonresponse during the initial interview (referred to as initiation) is addressed by introducing nonresponse adjustments that redistribute the weights of nonrespondents to responding sample units in the same ownership, industry, size class, and area. For example, if the nonresponding establishment was in the manufacturing industry and had an employment of 350 workers, the NCS would adjust the weights of responding manufacturing establishments with 100 499 workers by a nonresponse factor calculated by dividing the sum of the product of establishment employment and sample weight for responding and nonresponding establishments by the sum of the product of establishment employment and sample weight for responding establishments.
Step 2.Quote nonresponse adjustment. Quote nonresponse is a situation in which an establishment refuses to provide any wage data for a given sampled occupation (quote). Quote nonresponse during the initial interview is addressed by an adjustment that redistributes the weights of nonresponding quotes to responding sample quotes in the same occupational group, ownership, industry, size class, and area. Quote nonresponse during an update interview is addressed by imputation.
Step 3.Item imputation. Item nonresponse is a situation in which an establishment responds to the survey but is unable or unwilling to provide some or all of the benefits data for a given sampled occupation. Item nonresponse is addressed through item imputation in certain situations. Item imputation replaces missing values for an item with values derived from similar occupations and establishments with similar characteristics.
For benefit estimates, items can be imputed for nonresponse at initial and subsequent data collection. For example, during the initial contact, an establishment reports wage and salary data for a sampled occupation but refuses or is unable to report whether those in the occupation receive paid vacation benefits; the NCS imputes the incidence of vacation benefits for the selected occupation on the basis of the incidence of vacation benefits among similar occupations in similar establishments.
Additional adjustment factors are applied to special situations that may have occurred during data collection. For example, when a sample unit is one of two establishments owned by a given company and the respondent provides data for both locations combined instead of data for the sampled unit, the weight of the sampled unit is adjusted to reflect the employment data for the sampled unit.
Step 4.Benchmarking (poststratification). Benchmarking is the process of adjusting the weight of each establishment in the survey to match the most current distribution of employment by industry.
The NCS establishment sample is drawn from the Quarterly Census of Employment and Wages (QCEW). The QCEW and railroad information from the Railroad Retirement Board and Surface Transportation Board provide employment data, but because these sources do not have current employment data, the Current Employment Statistics (CES) program data are used to adjust employment. The benchmark process updates the initial establishment weights, assigned during sampling, by current employment. Establishment weights reflect employment at the time of sampling, not collection. Benchmarking ensures that survey estimates reflect the most current industry composition employment counts in proportions consistent with the private industry, state government, and local government sectors. The private industry sample also uses establishment employment size class in the benchmarking process.
For example, 40 private industry, 10 local government, and 5 state government units in the service sector were selected from the sampling frame made up of establishments employing 200,000 private workers, 30,000 local government workers, and 10,000 state government workers. By the time of survey processing, the private service sector employment increased by 10,000 workers, or 5 percent, with no increase in employment in the service sectors of state and local government. In the absence of benchmarking, the sample would underrepresent current employment in the private industry service sector. In this example, the NCS adjusts the sample weights of the 40 service sector firms in private industry to ensure that the number of workers in establishments in the sampling frame rises to 210,000. The ownership employment counts for the private industry service sector would then reflect the current proportions of 84 percent for private industry, 12 percent for local government, and 4 percent for state government employment.
Two types of errors are possible in an estimate based on a sample survey: sampling errors and nonsampling errors. Sampling errors occur because the sample makes up only a part of the population it represents. The sample used for the survey is one of a number of possible samples that could have been selected under the sample design, each producing its own estimate. A measure of the variation among sample estimates is the standard error. Nonsampling errors are data errors that stem from any source other than sampling error, such as data collection errors and data processing errors.
Standard errors can be used to measure the precision with which an estimate from a particular sample approximates the expected result of all possible samples. The chances are about 68 out of 100 that an estimate from the survey differs from a complete population figure by less than the standard error. The chances are about 90 out of 100 that this difference is less than 1.6 times the standard error. Statements of comparison appearing in Employee Benefits publications are significant at a level of 1.6 standard error or better. This means that, for differences cited, the estimated difference is less than 1.6 times the standard error of the difference. To assist users in evaluating the reliability of benefit estimates, standard errors are available for incidence estimates.
Employee Benefits uses a variation of balanced repeated replication (BRR), a methodology employed to estimate the standard error. The procedure for BRR entails first partitioning the sample into 120 variance strata composed of a single sampling stratum or clusters of sampling strata, and then splitting the sample units in each variance stratum evenly into two variance primary sampling units (PSUs). Next, half-samples are chosen, so that each contains exactly one variance PSU from each variance stratum. Choices are not random, but are designed to yield a balanced collection of half-samples. For each half-sample, a replicate estimate is computed with the same formula for the regular, or full-sample, estimate, except that the final weights are adjusted. A total of 120 replicates are used in this process. If a unit is in the half-sample, its weight is multiplied by (2 k); if not, its weight is multiplied by k. For all NCS publications, k = 0.5, so the multipliers are 1.5 and 0.5.
The BRR estimate of the standard error with R half-sample replicates is
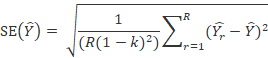
where
the summation is over all half-sample replicates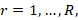 ;
;
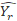 is the
is the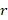 th half-sample replicate estimate; and
th half-sample replicate estimate; and
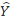 is the full-sample estimate.
is the full-sample estimate.
Data collection and processing errors are mitigated primarily through quality assurance programs that include the use of data collection reinterviews, observed interviews, computer edits of the data, and a systematic professional review of the data. The programs also serve as a training device to provide feedback to field economists, or data collectors, on errors and the sources of errors that can be remedied by improved collection instructions or computer-processing edits. Field economists receive extensive training to maintain high standards in data collection.
Before estimates are declared fit for use in BLS publications, estimates are validated. This process compares estimates with expected values derived from historical trends, economic conditions and indicators, changes in legislation (such as minimum wage or leave requirements), labor-management disputes, sample composition, sample rotation, changes in compensation structure, etc. Validation evaluates estimates based on individual establishment and worker domains.