
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
Crossref 0
Inequality of Income and Consumption in the U.S.: Measuring the Trends in Inequality from 1984 to 2011 for the Same Individuals, Review of Income and Wealth, 2015.
Although the Bureau of Labor Statistics (BLS) has imputed income in the Consumer Expenditure Interview Survey since 2004, imputed income data for previous years are unavailable. By closely mimicking the BLS imputation methodology, we address this gap by imputing income back to 1984. In this article, we describe our methodology and provide descriptive results showing the relative quality of our imputation. Our data and the statistical programs used to generate them will eventually be shared with the research community.
Researchers have long criticized the income variables in the Consumer Expenditure Survey (CE). For example, Orazio Attanasio, Erik Hurst, and Luigi Pistaferri have argued that income in the CE has more error in it than does income in the Panel Study of Income Dynamics (PSID).1 As the names of the surveys indicate, the primary purpose of the PSID is to capture income, whereas that of the CE is to capture expenditures, with income being a supplemental variable. Researchers who study income and consumption inequality use the CE for consumption and the Current Population Survey (CPS) for income, even though the CE has income data. For this reason (and others), the CE began imputing income in 2004,2 but it did not go back to impute income in previous years. We fill this gap by imputing income back to 1984 in the CE Interview Survey, using a methodology similar to that used by the Bureau of Labor Statistics (BLS).3
Jonathan Fisher has shown that CE respondents who have at least one source of income imputed are different from respondents who have valid reports for all sources of income.4 Researchers who want to use data before and after 2004 have two options, both of which are undesirable: (1) continue to use complete income reporters5 for every year and ignore imputed income (even though it is available starting in 2004); or (2) use all households, starting in 2004, but use only complete income reporters before 2004. Fisher has warned against the second option because it could create a break in any time series, as he has found to be the case for the poverty rate.6
By imputing income back to 1984, we remove the conundrum of whether to use the imputed income data starting in 2004. In separate research, we used these data to show that the trends in consumption and income inequality were similar between 1984 and 2006, but that these trends differed in the Great Recession of 2007–2009. In addition, we investigated the reasons for the divergence during the recession.7
In 2015, we will make our imputed income data, along with the Stata programs used to generate them, publicly available for researchers. Below, we describe our data and methodology. We also describe instances in which our methodology differs from the CE’s methodology and the reasons for our deviating. Then, we conduct three sets of tests to judge the quality of our imputation.
First, we compare our imputation results to the CE’s imputations from 2004 to 2012. By comparing these results, we check whether our methodology approximates that of the CE. Second, we impute income for CE respondents who had no income sources imputed and compare the actual reported value of income to our imputation. The comparison indicates whether our imputation matches the actual reports for those who validly reported income. Lastly, we compare our imputation results to income from the CPS. The CPS is considered a better source of income data than the CE is, even though the CPS has drawbacks of its own and should not be considered a gold standard for income reporting.
Our comparisons focus on four points in the distribution—10th percentile, median, mean, and 90th percentile—along with a measure of income inequality, the Gini coefficient. Where feasible, we also present full density distributions and scatterplots of our results to enhance the comparisons. Further work is needed to test how our imputed income would perform in a multivariate model.
The CE has been a continuous quarterly survey since 1980. Data are collected from consumer units (i.e., households) five times over a 13-month period. The survey’s second through fifth interviews are used to collect expenditure information for the previous 3 months. Our analysis begins in 1984, because this is the first year with the most consistently comparable data over time. Although the continuous CE began in 1980, not all variables (e.g., rental equivalence) were consistently collected between 1980 and 1984, and the sample excluded rural households in 1982 and 1983. We have data available through the first quarter of 2012.8
What is often overlooked or not understood by researchers is that the expenditure data are imputed in the CE when respondents indicated they purchased an item but failed to report a valid value for that purchase. By imputing income, we treat the income data the same way the consumption data are treated. While previous research has removed incomplete income reporters, no previous research has removed incomplete consumption reporters.
We impute income when the consumer unit reported receiving income but failed to provide a valid value for it. Unless otherwise stated, our methodology follows the CE’s methodology as we understand it.
We impute any income variable with an “invalid nonresponse” flag or a “don’t know/refuse” flag.9 Twelve family-level income variables are imputed: interest income, pensions and annuities, financial income (e.g., dividends and royalties), alimony, child support,10 lump-sum payments, unemployment, food stamps,11 welfare, net income or loss from roomers or boarders, net income or loss from other rental units, and other income (e.g., cash scholarships and cash stipends). We impute lump-sum income,12 whereas the CE does not. The official CE definition of before-tax income does not include lump-sum income, and the CE imputes only the components of before-tax income.
Five member-level income variables are imputed: wage and salary, Supplemental Security Income benefits, income or loss from a household member’s own farm, income or loss from a household member’s own nonfarm business, and social security and railroad retirement income. We deviate from the CE’s treatment of social security and railroad retirement income. The CE imputes the last payment received for these items, and its imputation captures whether Medicare premiums were subtracted from the last payment. It then multiplies that amount by the total number of payments received over the previous 12 months. Instead, we impute social security and railroad income earned over the previous 12 months. Ultimately, we are interested in the income over the last 12 months and do not need to know the three intermediate inputs.
The CE introduced income-bracket variables in the second quarter of 2001. If the respondent refused to provide an exact dollar value for an income source, he or she was asked to provide an answer from a bracketed range. From 2001 to 2003, the respondent was given the median of the valid reports over the last 3 years. Since 2004, the CE has imputed the value for bracketed income but restricted that value to the bracketed range. We deviate from the CE restriction and continue to use the median of the valid reports.
The CE also imputes income for a portion of consumer units who report a valid zero value for each income source listed above, excluding lump-sum income.13 The CE refers to these consumer units as “all valid blanks” (AVBs). Approximately 2 percent of all consumer units are classified as AVBs in the public-use data. Because the income questions are at the end of the survey, the CE program is concerned that some respondents may report no income as a way to end the survey.
We follow the CE methodology in estimating a likelihood of receipt for each income source for AVBs.14 The dependent variable equals 1 if the consumer unit received income from a given source and 0 otherwise. The independent variables used in the AVB process are the same as those used in the imputation process. After logit estimation, a likelihood of receipt is estimated for each AVB. A random number is then generated for each AVB and for each income source. If the predicted likelihood of receipt is greater than or equal to the random number, the valid blank for a given source is changed to an invalid blank. All invalid blanks generated from the AVB process are then treated as any other invalid blank and imputed for that source.
Following the basic methodology of Donald Rubin,15 we multiply impute the income data. Coefficients are estimated using the valid reporters. The estimated coefficients are then shocked, and the shocked coefficients are used to estimate a predicted value for the invalid reporters. To arrive at the final value, the predicted value is also shocked. Five implicates are generated for each income source with the use of the Stata mi impute command.16 Rather than use Ordinary Least Squares to generate the coefficients, we follow the CE methodology and use predictive mean matching, which matches the missing value with the mean of its nearest neighbors.17 All models are weighted, and all data used in the imputation are in real 2010 dollars.
Variables. The dependent variable equals the transformed level of the income source for all valid, “nonzero” respondents (i.e., respondents who report a valid positive or negative income value). We follow the CE methodology by first finding the median for each income source and then subtracting the median from the reported value. In this way, the transformed median for each income source becomes zero. The variables are transformed before the model is run, and the median is added back after the predicted values are obtained.
A large list of independent variables is included in each model. The list follows that of the CE, but we use different transformations for some variables. We include the following continuous variables: quadratic in age,18 transformed total expenditures (ERANKMTH),19 and a quadratic time trend. For the member-level income sources, we also include usual hours worked and weeks worked over the last 52 weeks.
We use the following categorical variables in the family-level model: race,20 education,21 urban/rural status, number of earners in the consumer unit,22 occupation,23 family type,24 region, household tenure,25 and a series of dummy variables for receipt of all individual income sources other than the one being imputed. When imputing unemployment insurance, welfare benefits, and food stamps, we also include state dummy variables to capture variations in these programs across states.26 In addition, the member-level models include gender, marital status, and relationship to the reference person (e.g., spouse, child). The model for wage and salary income includes variables capturing whether a member contributed to an Individual Retirement Account or a 401(k)-type retirement plan in the last 12 months and whether the member’s employer or union contributed to his or her pension plan.
The CE uses backward induction to limit the number of independent variables included in the final model. That model runs with all variables, but variables whose coefficients are not statistically significant at the 15-percent level are removed. The model is run again on this limited set of variables. If any variables are no longer statistically significant at the 15-percent level, they are removed. This iterative process continues until all variables remain statistically significant at the 15-percent level. We do not follow this process; instead, we use all variables, at all times. Although some variables are not statistically significant at some relatively low level, they presumably provide useful information and are correlated with the dependent variable.
Finally, when an income source is not allowed to be negative but its imputed value is negative or zero, we bottom code that source at $1.
Sample. Following the CE methodology, our imputation uses the current quarter and the previous 19 quarters of data. This approach presents a problem only in the early years of our study period, where data are not available for 19 previous quarters. For those years, we pool the 20 earliest quarters and use one set of coefficients for all 20 quarters. The variable for quadratic time trend accounts for growth in income over time.
We use only respondents who appear in the fifth CE interview, because we are interested in those who complete all five interviews. The second-quarter interview also asks income questions and, in the future, we plan to impute income for all interviews.
We present three comparisons to judge the quality of our imputation. First, we compare the imputed income variables in the public-use CE microdata to our imputed results from 2004 to 2011. Then, we use the methodology described earlier to impute income for those who validly reported their income. These results allow us to compare the actual reports of income in the CE microdata to imputed results for the same households. Finally, we compare income from the CPS to our imputed results.
In the results presented below, “year” refers to the year in which income was received. All income questions ask about income received in the previous 12 months. We classify the income of those interviewed from January through June of year t as having been received in year t – 1 and the income of those interviewed from July through December in year t as having been received in year t.
Comparison 1—Comparing CE imputed income to our imputed income. We begin by comparing imputed income from the CE to our imputed income over the same period, from 2003 to 2011. This comparison shows whether the two imputation methodologies produce approximately the same results for overlapping years.
Figure 1 displays the 2003–2011 values of before-tax income at the 10th percentile, median, mean, and 90th percentile for the CE’s imputed income variable and our imputed income variable.27 (In all figures, the abbreviation “FJS” denotes results from our imputations.) The two series largely overlap over the entire period for all measures, except the 90th percentile. The biggest difference occurs in 2004, when our imputed income at the 90th percentile is approximately 4 percent lower than that in the CE. One potential explanation for this result is that we use top-coded income variables to impute, whereas the CE does not. Thus, our distribution is more compressed at the top.
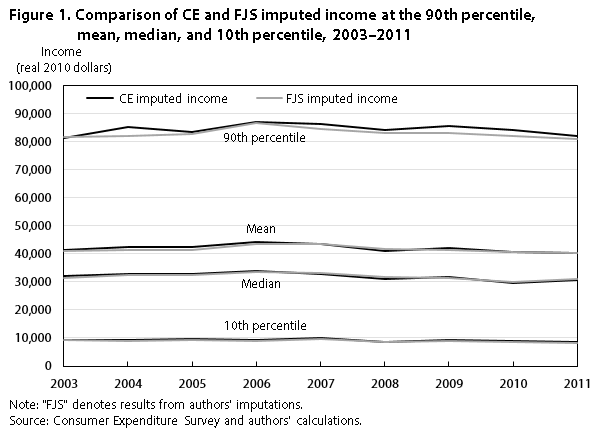
| Year | 90th percentile | Mean | Median | 10th percentile | ||||
|---|---|---|---|---|---|---|---|---|
| CE income | FJS income | CE income | FJS income | CE income | FJS income | CE income | FJS income | |
| 2003 | $81,294 | $81,581 | $41,288 | $41,131 | $31,981 | $31,553 | $9,176 | $9,159 |
| 2004 | 85,074 | 81,825 | 42,536 | 41,375 | 32,863 | 32,280 | 9,112 | 8,943 |
| 2005 | 83,357 | 82,590 | 42,289 | 41,314 | 32,792 | 32,300 | 9,468 | 9,163 |
| 2006 | 87,096 | 86,532 | 44,070 | 43,470 | 33,781 | 33,410 | 9,168 | 9,097 |
| 2007 | 86,348 | 84,359 | 43,429 | 43,381 | 32,707 | 33,126 | 9,847 | 9,495 |
| 2008 | 83,989 | 83,049 | 41,142 | 41,627 | 31,105 | 31,610 | 8,541 | 8,525 |
| 2009 | 85,703 | 83,007 | 41,938 | 41,446 | 31,791 | 31,421 | 9,187 | 8,884 |
| 2010 | 84,241 | 81,803 | 40,577 | 40,477 | 29,709 | 29,897 | 8,768 | 8,557 |
| 2011 | 82,014 | 80,788 | 40,288 | 40,258 | 30,607 | 30,873 | 8,592 | 8,222 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey and authors' calculations. | ||||||||
Figure 2 presents the Gini coefficient, which is a measure of income inequality. A Gini of 1.0 means complete inequality, whereas a Gini of 0.0 means complete equality. We present the Gini for the mean of the five implicates and the Gini for one of the implicates. As expected, the mean of the five implicates shows less inequality, because of a mean reversion resulting from averaging across the five implicates. Our Gini is below the CE Gini in some years but above it or right on in other years. Given the pattern in figure 1, where our 90th percentile value was lower than the CE’s 90th percentile value, we were concerned that our Gini would be consistently lower; however, this is not the case.
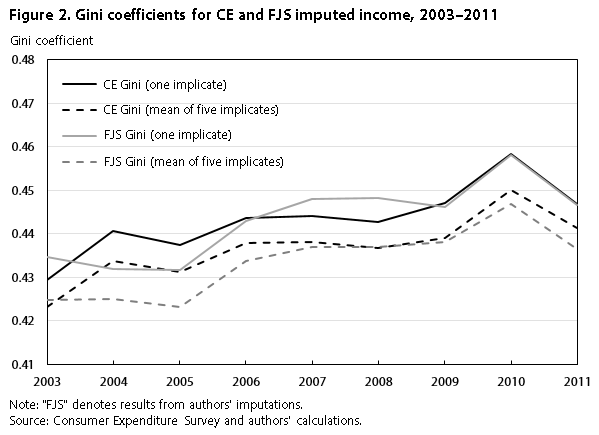
| Year | CE Gini (one implicate) | CE Gini (mean of five implicates) | FJS Gini (one implicate) | FJS Gini (mean of five implicates) |
|---|---|---|---|---|
| 2003 | 0.42938 | 0.42327 | 0.43458 | 0.42473 |
| 2004 | .44074 | .43374 | .43181 | .42495 |
| 2005 | .43737 | .43112 | .43170 | .42316 |
| 2006 | .44366 | .43779 | .44291 | .43385 |
| 2007 | .44410 | .43816 | .44795 | .43688 |
| 2008 | .44267 | .43667 | .44818 | .43708 |
| 2009 | .44704 | .43903 | .44618 | .43812 |
| 2010 | .45830 | .45015 | .45825 | .44690 |
| 2011 | .44680 | .44127 | .44653 | .43642 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey and authors' calculations. | ||||
Figure 3 shows the de-meaned Gini coefficients,28 along with a 95-percent confidence interval. Although the levels of inequality for our imputed income and the CE imputed income are not identical, the difference is not statistically significant.
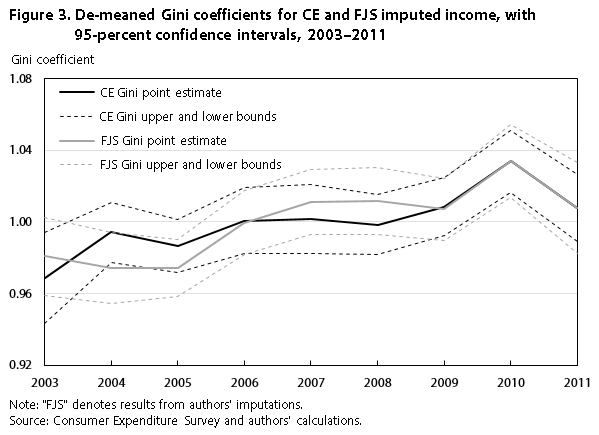
| Year | CE Gini | FJS Gini | ||||
|---|---|---|---|---|---|---|
| Lower bound | Point estimate | Upper bound | Lower bound | Point estimate | Upper bound | |
| 2003 | 0.94294 | 0.96851 | 0.99407 | 0.95904 | 0.98073 | 1.00239 |
| 2004 | .97734 | .99414 | 1.01091 | .95463 | .97447 | .99430 |
| 2005 | .97158 | .98653 | 1.00147 | .95827 | .97423 | .99016 |
| 2006 | .98204 | 1.00072 | 1.01941 | .98147 | .99952 | 1.01758 |
| 2007 | .98240 | 1.00171 | 1.02104 | .99283 | 1.01090 | 1.02895 |
| 2008 | .98186 | .99849 | 1.01514 | .99270 | 1.01142 | 1.03015 |
| 2009 | .99211 | 1.00835 | 1.02459 | .98936 | 1.00690 | 1.02443 |
| 2010 | 1.01640 | 1.03374 | 1.05107 | 1.01369 | 1.03414 | 1.05458 |
| 2011 | .98921 | 1.00780 | 1.02642 | .98210 | 1.00769 | 1.03329 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey and authors' calculations. | ||||||
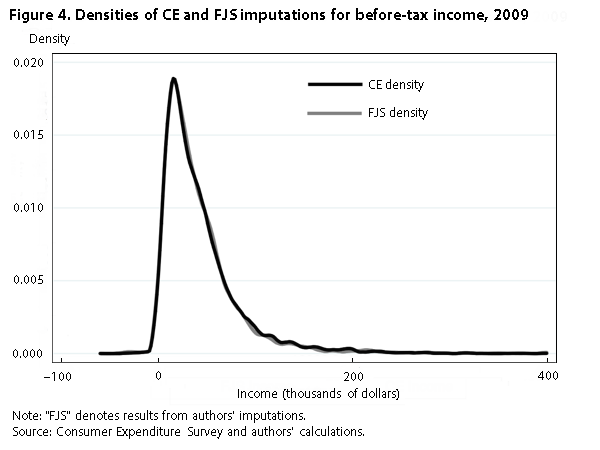
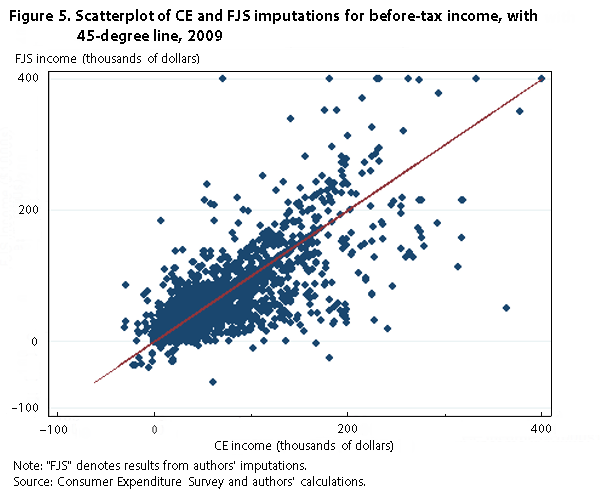
Figure 4 displays the full densities for our income variable and the CE income variable for 2009. The two variables largely overlap, except at the right tail of the distribution, matching the finding from figure 1. Another way to compare the distributions is with the scatterplot shown in figure 5. If our imputation matched the CE imputation exactly, all observations would lie along the 45-degree line displayed in the figure. Although the scatterplot is relatively tight along the 45-degree line, there are some outliers throughout the distributions. The correlation between the two income variables is .84.
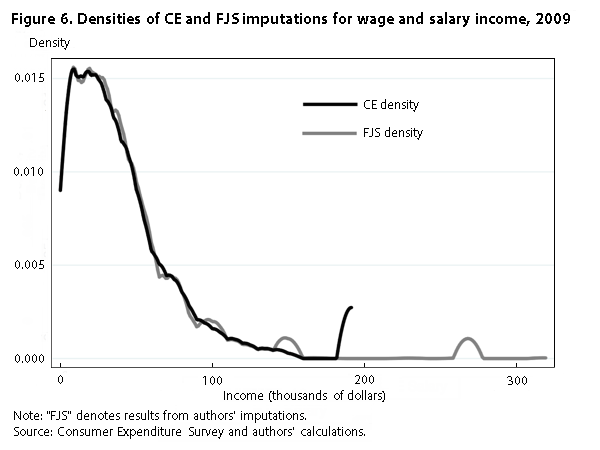
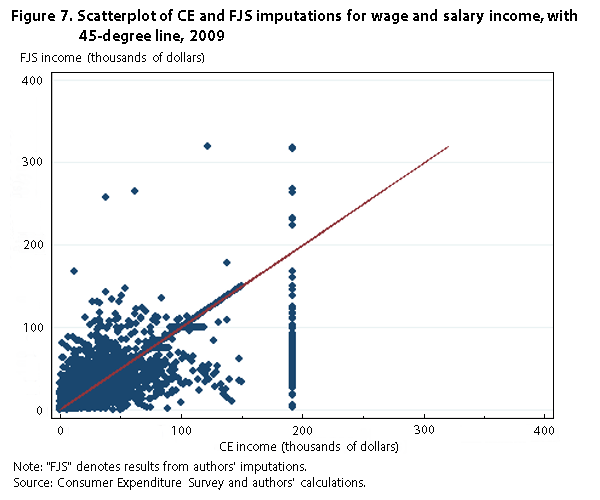
Finally, we compare our imputed wage and salary income to that of the CE, presenting densities and a scatterplot analogous to those presented earlier. (See figures 6 and 7.) We focus on wage and salary income because it is the biggest source of income for most households. For this comparison, the unit of observation is the individual, not the household. Interestingly, our wage and salary distribution has a longer right tail than does the CE distribution, because we do not reimpose the top codes after imputation. The correlation between the two variables is .87.
The test in this first comparison shows only that our imputation matches the CE’s imputation. It does not indicate whether our imputation is accurate in itself. The next two comparisons help us determine the quality of our imputation.
Comparison 2—Imputing for valid reporters. In this comparison, we test how well our methodology imputes income for those in the CE who actually reported a valid value for an income source. For example, we take those who reported a valid nonzero value for wage and salary income in the first quarter of 2011 and treat them as if their income needed to be imputed. We use the previous 20 quarters of wage and salary reports and repeat the procedure for every income source and for every quarter.
With these new imputed values, we can compare the actual income reported in the CE to the imputed value. Because we are interested in total income and less so in the individual sources of income, we focus mainly on comparing total before-tax income. Therefore, our comparison includes those who reported a valid value for each source of income and had no imputation. We refer to this type of survey respondents as “full income reporters.” We might prefer to use the term “complete income reporters;” however, that term has its own confusing terminology in the CE lexicon. Our indicator of full income reporters is as strict as it can be—the household must have a valid report for each source of income. A zero can be a valid value.29
Figure 8 compares actual income of full income reporters with our imputation of all sources of income for these households at various points on the distribution. We do best at the mean and the 90th percentile, where our imputation is within 5 percent of the true value in all but 1 year for the mean and all but 3 years for the 90th percentile. In most years, our imputation is considerably higher at the 10th percentile, suggesting that we have difficulty imputing smaller values for those who received the income source. This pattern is different from that displayed in figure 1, where our imputation was right on at the 10th percentile but lower at the 90th percentile.
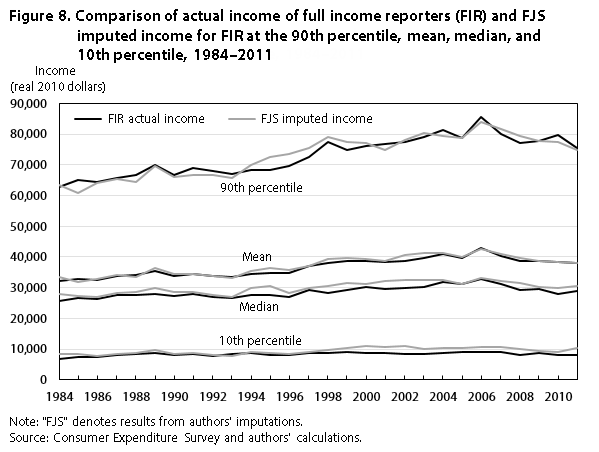
| Year | 90th percentile | Mean | Median | 10th percentile | ||||
|---|---|---|---|---|---|---|---|---|
| FIR income | FJS income | FIR income | FJS income | FIR income | FJS income | FIR income | FJS income | |
| 1984 | $62,738 | $63,566 | $32,025 | $33,339 | $25,656 | $27,791 | $6,838 | $8,396 |
| 1985 | 64,925 | 60,865 | 32,987 | 31,981 | 26,500 | 27,394 | 7,389 | 8,262 |
| 1986 | 64,523 | 64,126 | 32,513 | 32,720 | 26,166 | 26,823 | 7,399 | 7,726 |
| 1987 | 65,641 | 65,541 | 33,684 | 34,017 | 27,582 | 28,286 | 7,943 | 8,508 |
| 1988 | 66,806 | 64,323 | 34,240 | 33,468 | 27,761 | 28,471 | 8,317 | 8,638 |
| 1989 | 69,995 | 69,698 | 35,427 | 36,536 | 28,026 | 29,826 | 8,851 | 9,869 |
| 1990 | 66,694 | 65,936 | 33,729 | 34,350 | 27,233 | 28,539 | 8,168 | 8,491 |
| 1991 | 68,967 | 66,836 | 34,511 | 34,588 | 27,801 | 28,609 | 8,314 | 8,585 |
| 1992 | 67,978 | 66,820 | 33,681 | 33,836 | 27,061 | 27,719 | 7,740 | 8,065 |
| 1993 | 67,099 | 65,727 | 33,587 | 33,108 | 26,718 | 26,895 | 8,286 | 7,706 |
| 1994 | 68,440 | 69,849 | 34,450 | 35,289 | 27,611 | 29,886 | 8,706 | 8,987 |
| 1995 | 68,302 | 72,467 | 34,735 | 36,537 | 27,632 | 30,711 | 8,210 | 8,742 |
| 1996 | 69,697 | 73,612 | 34,915 | 35,861 | 27,045 | 28,134 | 7,979 | 8,328 |
| 1997 | 72,429 | 75,637 | 37,059 | 37,157 | 29,204 | 29,767 | 8,823 | 9,178 |
| 1998 | 77,484 | 79,043 | 37,885 | 39,295 | 28,277 | 30,462 | 8,749 | 9,714 |
| 1999 | 74,785 | 77,350 | 38,673 | 39,678 | 29,388 | 31,445 | 9,086 | 10,477 |
| 2000 | 76,210 | 77,191 | 38,698 | 39,508 | 30,364 | 31,361 | 8,747 | 10,916 |
| 2001 | 76,703 | 74,814 | 38,371 | 38,698 | 29,536 | 32,142 | 8,743 | 10,614 |
| 2002 | 77,540 | 78,196 | 38,832 | 40,669 | 29,851 | 32,382 | 8,493 | 11,081 |
| 2003 | 79,135 | 80,324 | 39,790 | 41,273 | 30,238 | 32,654 | 8,312 | 10,021 |
| 2004 | 81,181 | 79,372 | 41,050 | 41,208 | 31,918 | 32,395 | 8,900 | 10,222 |
| 2005 | 78,667 | 78,749 | 39,746 | 39,869 | 31,088 | 31,325 | 8,984 | 10,319 |
| 2006 | 85,451 | 83,953 | 43,011 | 42,619 | 32,841 | 33,197 | 9,089 | 10,615 |
| 2007 | 79,907 | 81,820 | 40,309 | 41,012 | 31,352 | 32,284 | 9,073 | 10,678 |
| 2008 | 77,012 | 79,475 | 38,596 | 39,642 | 29,306 | 31,580 | 8,007 | 9,974 |
| 2009 | 77,732 | 77,778 | 38,770 | 38,847 | 29,441 | 30,264 | 8,588 | 9,454 |
| 2010 | 79,557 | 77,595 | 38,336 | 38,294 | 27,913 | 30,027 | 8,140 | 9,061 |
| 2011 | 75,611 | 74,901 | 38,086 | 38,186 | 29,083 | 30,658 | 8,195 | 10,360 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey and authors' calculations. | ||||||||
Figure 9 reports how well we match the trends in income inequality. The year 1993 is the only year for which the de-meaned trends show a statistically significant difference at the 5-percent level. The figure suggests that our imputation methodology does a decent job of capturing the de-meaned trends in inequality over the 1984–2011 period.
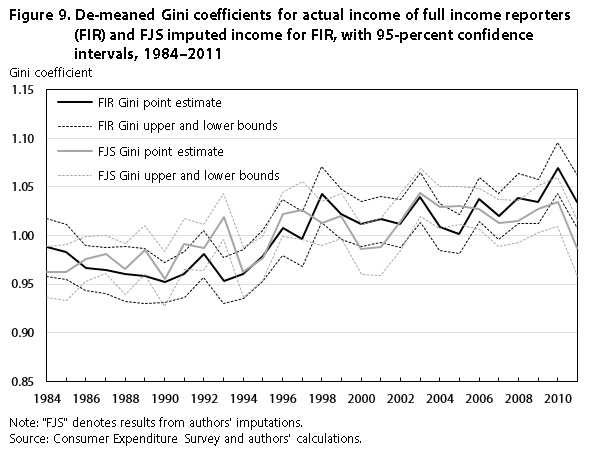
| Year | FIR Gini | FJS Gini | ||||
|---|---|---|---|---|---|---|
| Lower bound | Point estimate | Upper bound | Lower bound | Point estimate | Upper bound | |
| 1984 | 0.95802 | 0.98799 | 1.01796 | 0.93650 | 0.96280 | 0.98911 |
| 1985 | .95443 | .98275 | 1.01105 | .93327 | .96218 | .99110 |
| 1986 | .94339 | .96655 | .98970 | .95319 | .97624 | .99927 |
| 1987 | .94038 | .96407 | .98778 | .96100 | .98073 | 1.00044 |
| 1988 | .93217 | .96046 | .98872 | .93981 | .96588 | .99196 |
| 1989 | .93038 | .95833 | .98628 | .95981 | .98513 | 1.01046 |
| 1990 | .93134 | .95191 | .97250 | .92731 | .95535 | .98339 |
| 1991 | .93665 | .95994 | .98322 | .96465 | .99129 | 1.01793 |
| 1992 | .95678 | .98119 | 1.00558 | .96353 | .98722 | 1.01092 |
| 1993 | .93044 | .95366 | .97690 | .99578 | 1.01935 | 1.04291 |
| 1994 | .93530 | .96034 | .98537 | .93664 | .96222 | .98781 |
| 1995 | .95323 | .97923 | 1.00523 | .95393 | .97664 | .99934 |
| 1996 | .97907 | 1.00785 | 1.03662 | .99900 | 1.02175 | 1.04450 |
| 1997 | .96828 | .99633 | 1.02437 | .99554 | 1.02579 | 1.05606 |
| 1998 | 1.01338 | 1.04241 | 1.07143 | .98935 | 1.01238 | 1.03540 |
| 1999 | .99640 | 1.02213 | 1.04786 | .99686 | 1.02029 | 1.04373 |
| 2000 | .98895 | 1.01179 | 1.03463 | .96040 | .98569 | 1.01100 |
| 2001 | .99306 | 1.01687 | 1.04066 | .95901 | .98844 | 1.01788 |
| 2002 | .98778 | 1.01231 | 1.03682 | .98456 | 1.01404 | 1.04355 |
| 2003 | 1.01381 | 1.03932 | 1.06483 | 1.01930 | 1.04408 | 1.06884 |
| 2004 | .98488 | 1.00898 | 1.03309 | 1.00749 | 1.02918 | 1.05090 |
| 2005 | .98119 | 1.00166 | 1.02213 | 1.01138 | 1.03071 | 1.05002 |
| 2006 | 1.01485 | 1.03748 | 1.06012 | 1.00582 | 1.02694 | 1.04803 |
| 2007 | .99641 | 1.01991 | 1.04342 | .98923 | 1.01297 | 1.03670 |
| 2008 | 1.01253 | 1.03819 | 1.06387 | .99254 | 1.01449 | 1.03646 |
| 2009 | 1.01248 | 1.03491 | 1.05733 | 1.00311 | 1.02736 | 1.05163 |
| 2010 | 1.04336 | 1.06931 | 1.09527 | 1.00900 | 1.03408 | 1.05918 |
| 2011 | 1.00685 | 1.03413 | 1.06142 | .95767 | .98677 | 1.01587 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey and authors' calculations. | ||||||
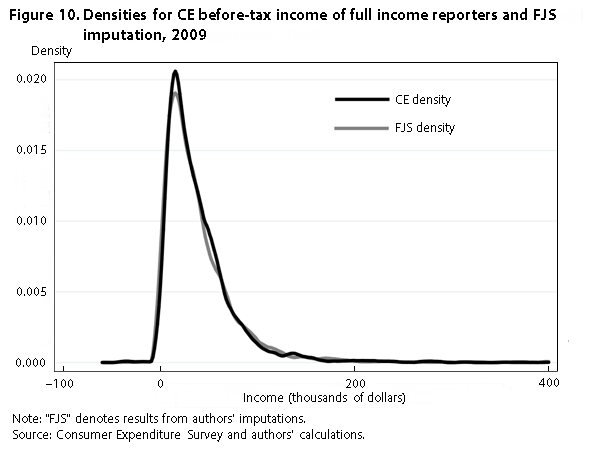
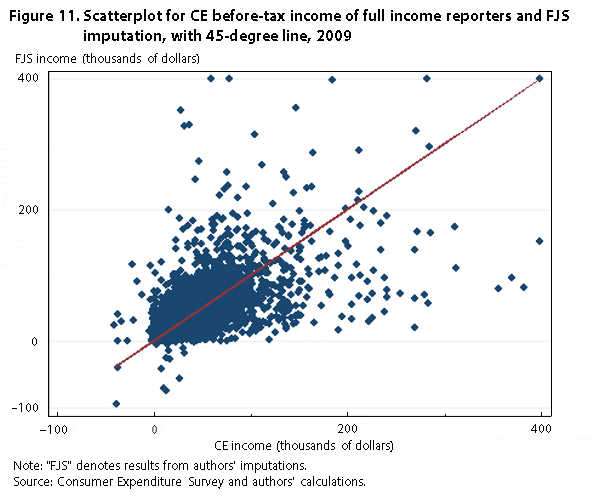
Figure 10 shows a pattern similar to that observed in figure 8. Our imputation is a little higher on the bottom end of the distribution but similar to CE income across the rest of the distribution. Compared with figure 5, the scatterplot for the two series in figure 11 shows more spread away from the 45-degree line, but the correlation coefficient between the two variables is still high, at .62.
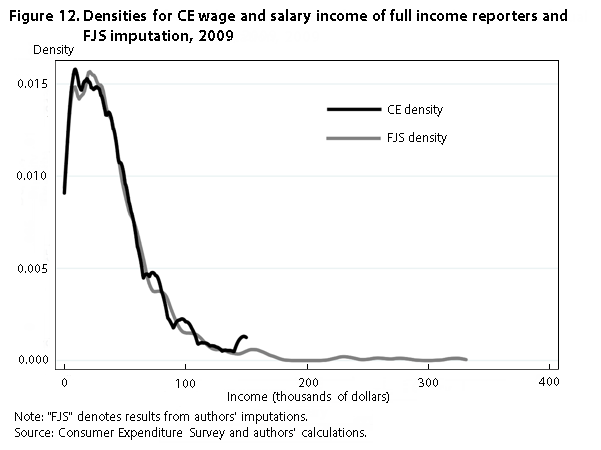
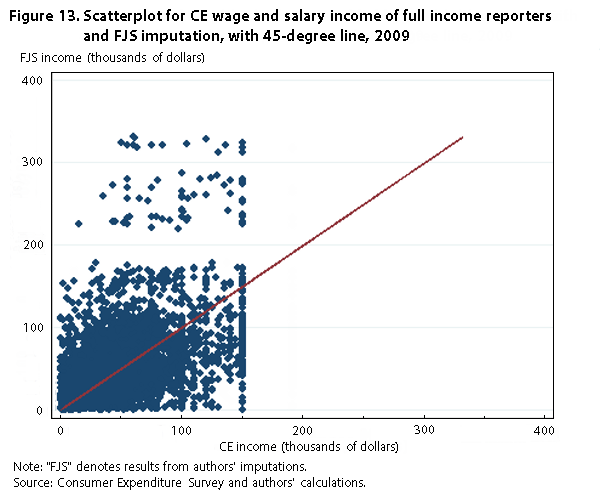
Finally, figures 12 and 13 show the densities and the scatterplot, respectively, for wage and salary income in 2009 for full income reporters and our imputation. As before, the top-coding affects the full income reporters without constraining our imputed values for these individuals. This result explains both why our distributions have a longer right tail and the censoring seen on the x-axis in figure 13. The correlation between the two wage variables is relatively strong, with a correlation coefficient of .62.
Comparison 3—Comparison to the Current Population Survey. As a final test of the quality of our imputation, we compare our results to income from the CPS Annual Social and Economic Supplement (ASEC).30 When it comes to the collection of income data, the ASEC has two main advantages over the CE: (1) its focus is on income, whereas that of the CE is on expenditures; and (2) it has a larger sample size, allowing for more precise estimation.
Research that looks at income and consumption inequality usually uses the CPS for income.31 The CPS imputes income with the use of a “hot deck” methodology (i.e., duplication of other households’ responses). In the results presented here, we use imputed income from the CPS. For the CE, we revert to valid income values when these are reported by the household and to imputed values for invalid blanks. Although the CPS is not perfect, it does provide a point of comparison that is outside the CE.
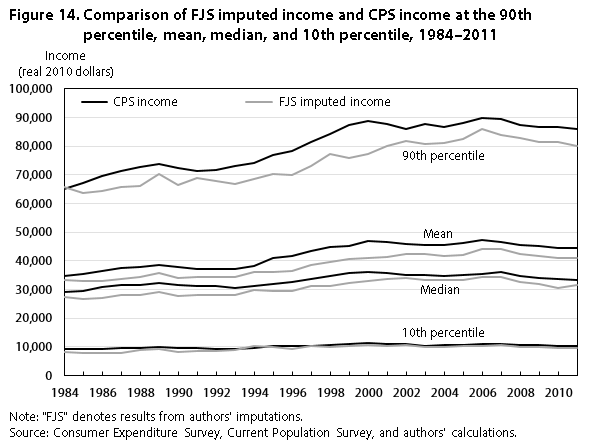
Figure 14 compares our income measure to that of the CPS at various points on the distribution. For each of our four points, our imputed income is equal to or lower than income in the CPS. On average, our estimates are about 8 percent lower than the corresponding values in the CPS.
| Year | 90th percentile | Mean | Median | 10th percentile | ||||
|---|---|---|---|---|---|---|---|---|
| CPS income | FJS income | CPS income | FJS income | CPS income | FJS income | CPS income | FJS income | |
| 1984 | $65,177 | $65,560 | $34,646 | $33,364 | $29,046 | $27,401 | $9,140 | $8,183 |
| 1985 | 66,955 | 63,459 | 35,240 | 32,849 | 29,517 | 26,833 | 9,247 | 7,894 |
| 1986 | 69,497 | 64,500 | 36,591 | 32,991 | 30,690 | 27,095 | 9,293 | 7,835 |
| 1987 | 71,210 | 65,604 | 37,376 | 33,747 | 31,578 | 28,080 | 9,433 | 7,787 |
| 1988 | 72,633 | 66,055 | 37,820 | 34,251 | 31,697 | 28,167 | 9,572 | 8,723 |
| 1989 | 73,853 | 70,256 | 38,616 | 35,612 | 32,300 | 29,024 | 9,976 | 9,114 |
| 1990 | 72,208 | 66,293 | 37,719 | 34,015 | 31,535 | 27,801 | 9,724 | 8,345 |
| 1991 | 71,203 | 68,873 | 37,151 | 34,482 | 31,072 | 27,933 | 9,494 | 8,434 |
| 1992 | 71,667 | 67,850 | 37,127 | 34,395 | 31,080 | 28,135 | 9,362 | 8,405 |
| 1993 | 73,202 | 66,752 | 37,187 | 34,216 | 30,550 | 28,024 | 9,160 | 8,849 |
| 1994 | 74,049 | 68,440 | 38,051 | 35,954 | 31,278 | 29,847 | 9,554 | 10,170 |
| 1995 | 76,925 | 70,100 | 40,997 | 36,019 | 32,058 | 29,542 | 10,106 | 9,898 |
| 1996 | 78,395 | 69,824 | 41,803 | 36,551 | 32,518 | 29,508 | 10,127 | 9,257 |
| 1997 | 81,540 | 73,111 | 43,307 | 38,376 | 33,544 | 31,216 | 10,289 | 10,114 |
| 1998 | 84,220 | 77,362 | 44,672 | 39,456 | 34,732 | 31,208 | 10,608 | 9,805 |
| 1999 | 87,435 | 75,688 | 45,247 | 40,523 | 35,636 | 32,204 | 11,123 | 10,413 |
| 2000 | 88,590 | 77,161 | 46,878 | 40,992 | 36,066 | 32,972 | 11,361 | 10,501 |
| 2001 | 87,639 | 79,866 | 46,587 | 41,392 | 35,567 | 33,542 | 11,084 | 10,216 |
| 2002 | 86,120 | 81,873 | 45,670 | 42,325 | 35,136 | 34,029 | 10,885 | 10,604 |
| 2003 | 87,751 | 80,754 | 45,523 | 42,215 | 34,993 | 33,171 | 10,245 | 9,925 |
| 2004 | 86,572 | 81,112 | 45,519 | 41,724 | 34,771 | 33,280 | 10,638 | 10,045 |
| 2005 | 88,156 | 82,436 | 46,182 | 41,961 | 35,125 | 33,319 | 10,769 | 10,334 |
| 2006 | 89,695 | 85,826 | 47,114 | 44,148 | 35,463 | 34,353 | 10,988 | 10,425 |
| 2007 | 89,338 | 83,993 | 46,584 | 43,932 | 35,955 | 34,210 | 10,869 | 10,619 |
| 2008 | 87,362 | 82,805 | 45,338 | 42,283 | 34,766 | 32,724 | 10,565 | 9,785 |
| 2009 | 86,784 | 81,549 | 45,037 | 41,671 | 34,054 | 31,791 | 10,478 | 9,972 |
| 2010 | 86,603 | 81,359 | 44,287 | 41,006 | 33,700 | 30,503 | 10,152 | 9,710 |
| 2011 | 86,058 | 79,878 | 44,425 | 40,918 | 33,212 | 31,570 | 10,125 | 9,664 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey, Current Population Survey, and authors' calculations. | ||||||||
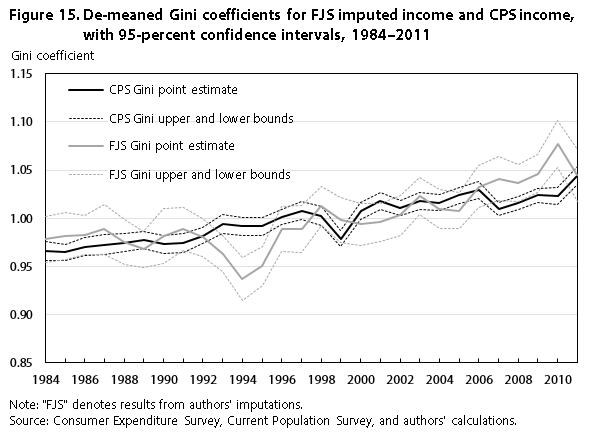
Figure 15 shows the de-meaned Gini coefficients from 1984 to 2011 for our imputation of CE income and the CPS income, along with the corresponding 95-percent confidence intervals. Except in 1994 and 2010, the two series exhibit no statistically significant difference, and their confidence intervals overlap. Choosing the end points as a frame of reference, we observe that, between 1984 and 2011, CPS income inequality increased by 8.1 percent while CE income inequality increased by 6.8 percent. However, it is not the case that the CE always shows a smaller increase in inequality, and choosing a different pair of years may produce a different result. For example, from 1984 to 2010, income inequality increased by 5.9 percent in the CPS and by 10.1 percent in the CE.
| Year | CPS Gini | FJS Gini | ||||
|---|---|---|---|---|---|---|
| Lower bound | Point estimate | Upper bound | Lower bound | Point estimate | Upper bound | |
| 1984 | 0.95623 | 0.96625 | 0.97626 | 0.95453 | 0.97811 | 1.00167 |
| 1985 | .95617 | .96469 | .97320 | .95782 | .98174 | 1.00568 |
| 1986 | .96142 | .97070 | .97997 | .96264 | .98300 | 1.00334 |
| 1987 | .96273 | .97275 | .98277 | .96289 | .98868 | 1.01445 |
| 1988 | .96527 | .97484 | .98443 | .95165 | .97515 | .99866 |
| 1989 | .96878 | .97745 | .98614 | .94897 | .96791 | .98684 |
| 1990 | .96381 | .97287 | .98196 | .95276 | .98150 | 1.01022 |
| 1991 | .96487 | .97467 | .98445 | .96628 | .98871 | 1.01111 |
| 1992 | .97344 | .98216 | .99087 | .96012 | .98019 | 1.00024 |
| 1993 | .98472 | .99449 | 1.00425 | .94444 | .96327 | .98208 |
| 1994 | .98223 | .99158 | 1.00093 | .91497 | .93705 | .95915 |
| 1995 | .98223 | .99158 | 1.00093 | .93021 | .95073 | .97124 |
| 1996 | .99314 | 1.00133 | 1.00953 | .96529 | .98886 | 1.01241 |
| 1997 | .99868 | 1.00794 | 1.01722 | .96488 | .98910 | 1.01331 |
| 1998 | .99296 | 1.00274 | 1.01254 | .99234 | 1.01274 | 1.03312 |
| 1999 | .97093 | .97898 | .98703 | .97448 | .99817 | 1.02188 |
| 2000 | .99866 | 1.00780 | 1.01694 | .97208 | .99370 | 1.01533 |
| 2001 | 1.00954 | 1.01811 | 1.02665 | .97641 | .99614 | 1.01588 |
| 2002 | 1.00270 | 1.01052 | 1.01834 | .98272 | 1.00338 | 1.02403 |
| 2003 | 1.00969 | 1.01832 | 1.02697 | 1.00387 | 1.02338 | 1.04289 |
| 2004 | 1.00800 | 1.01636 | 1.02471 | .98950 | 1.00952 | 1.02957 |
| 2005 | 1.01573 | 1.02376 | 1.03180 | .98953 | 1.00804 | 1.02657 |
| 2006 | 1.02092 | 1.02937 | 1.03783 | 1.01104 | 1.03281 | 1.05456 |
| 2007 | 1.00295 | 1.00992 | 1.01690 | 1.01843 | 1.04123 | 1.06405 |
| 2008 | 1.00930 | 1.01589 | 1.02245 | 1.01719 | 1.03662 | 1.05602 |
| 2009 | 1.01661 | 1.02376 | 1.03090 | 1.02635 | 1.04620 | 1.06603 |
| 2010 | 1.01441 | 1.02302 | 1.03162 | 1.05325 | 1.07739 | 1.10154 |
| 2011 | 1.03549 | 1.04440 | 1.05331 | 1.01799 | 1.04481 | 1.07164 |
| Note: "FJS" denotes results from authors' imputations. Source: Consumer Expenditure Survey, Current Population Survey, and authors' calculations. | ||||||
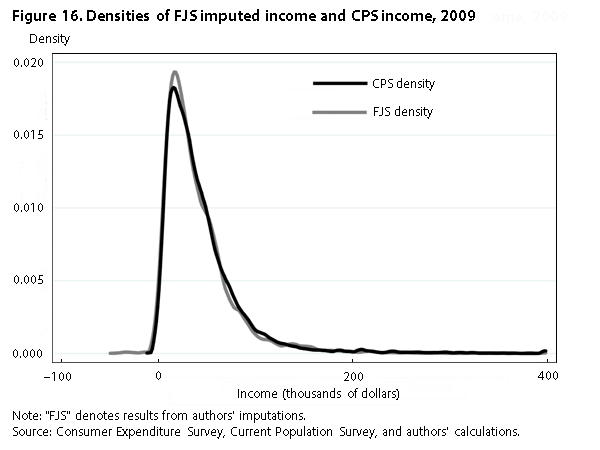
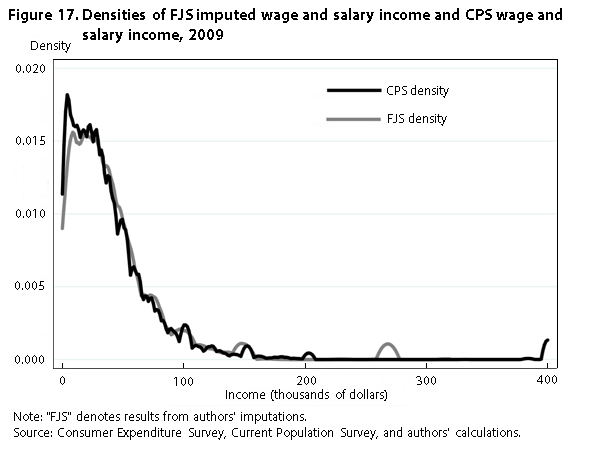
Figure 16 tells the same story as figure 14 does, showing that our imputed CE income is similar to the CPS income, except that our imputation is shifted to the left. Figure 17 shows the distributions of wage and salary income for the CPS and our imputed CE income. Although the CPS distribution has a longer right tail, the two densities generally overlap.
With this research, we provide a supplement to the public-use data of the CE Interview Survey by imputing income for those consumer units who failed to report a valid value for all of their income sources. We mimic the imputation methodology used by BLS as close as possible (with public-use data), and our series goes back to 1984 and continues through the latest year for which data are available. Eventually, we will make our data publicly available for researchers, and we hope to enlist BLS support to run similar imputations on the restricted-access CE data.
ACKNOWLEDGMENT: We would like to thank Laura Paszkiewicz and Geoffrey Paulin, both of the U.S. Bureau of Labor Statistics, for their help with income imputation.
!--?pagebreak?-->!--?pagebreak?-->!--?pagebreak?-->!--?pagebreak?-->!--?pagebreak?-->!--?pagebreak?-->Jonathan D. Fisher, David Johnson, and Timothy M. Smeeding, "Imputing income in the Consumer Expenditure Interview Survey," Monthly Labor Review, U.S. Bureau of Labor Statistics, November 2014, https://doi.org/10.21916/mlr.2014.37
1 See Orazio Attanasio, Erik Hurst, and Luigi Pistaferri, “The evolution of income, consumption, and leisure inequality in the US, 1980–2010,” working paper 17982 (National Bureau of Economic Research, 2012).
2 Income imputation refers to the process of estimating income values when they are not reported in the CE.
3 We have no plans to impute income in the CE Diary Survey.
4 See Jonathan Fisher, “Income imputation and the analysis of consumer expenditure data,” Monthly Labor Review, November 2006, pp. 11–19, https://www.bls.gov/opub/mlr/2006/11/art2full.pdf.
5 The term “complete income reporters” refers to survey respondents who provide sufficient income data for use in official publications.
6 Fisher, “Income imputation.”
7 See Jonathan Fisher, David Johnson, and Timothy Smeeding, “Inequality of income and consumption in the U.S.: measuring the trends in inequality from 1984 to 2011 for the same individuals,” Review of Income and Wealth (forthcoming, 2015). See also Jonathan Fisher, David Johnson, and Timothy Smeeding, “Exploring the divergence of consumption and income inequality during the Great Recession,” working paper presented at the 2014 American Economic Association Annual Meeting.
8 We use public-use CE files in this work. Although we report results through 2011, we are working on additional years of the CE Interview Survey, capturing data as they become available.
9 An “invalid nonresponse” is a nonresponse that is inconsistent with other data reported by the consumer unit. In the CE documentation, we impute income if the income source has a “B” or a “C” flag.
10 Before the third quarter of 1993, alimony and child support income were one variable. When feasible, the two income sources are treated separately, in accordance with the methodology described here.
11 Since the second quarter of 2001, the food stamp variable has included food stamps and electronic benefits. The variable also changed names at that time.
12 Lump-sum income includes lump-sum payments from estates, trusts, royalties, alimony, prizes, games of chance, and payments from people outside the consumer unit.
13 Before the second quarter of 2001, the food stamp variable did not allow for valid blanks, a flag code of “A”. Instead, consumer units were given a zero for the food stamp variable, and the flag indicated a valid value, a flag code of “D”. We treat these consumer units as “valid zeroes.”
14 The AVB process is not performed for wage and salary income, farm income or loss, and nonfarm business income or loss. If a respondent reports being employed but fails to report wage and salary income, he or she has an invalid blank and that source is imputed. If a respondent is not employed, he or she has a valid blank. Thus, a respondent with a valid blank for wage and salary income could not have received wage and salary income, because that individual was not working; hence, we refrain from changing the valid blank to an invalid blank. Similar logic applies to farm and nonfarm business income.
15 See Donald B. Rubin, Multiple imputation for nonresponse in surveys (New York: John Wiley and Sons, Inc., 1987).
16 It is understood that the CE program uses SAS for its imputation.
17 It is not known whether the CE program uses Ordinary Least Squares or another method to generate the coefficients.
18 For the family-level variables, the individual-specific demographic characteristics (e.g., age, race) are for the reference person.
19 The variable ERANKMTH is transformed with the use of the same methodology as that used to transform the dependent variables. Since the variable does not appear in the public-use files before the second quarter of 1994, the CE program office provided us with its values from 1987 to the first quarter of 1994. It also provided us with the variable's values from 2004 to 2006, because the values on file in this period are affected by imputation. For the 1984–1986 period, ERANKMTH was calculated from the MTAB file.
20 The variable for member-level race separated Asians from Pacific Islanders in the first quarter of 2003. To remain consistent, we grouped these two categories in all years. Also in the first quarter of 2003, the variable for race of the reference person included an additional category for “multiple races.” This coding was retained because it was not feasible to perform a recoding that would make the race variables agree.
21 Five categories were created for education: less than high school, high school, some college, college, and graduate degree.
22 Four categories were created for number of earners: 0, 1, 2, and 3+.
23 Additional occupational categories were included, starting in 1994. The categories were collapsed to match earlier data.
24 Although the CE program imputes income by family type (e.g., husband and wife with the youngest child under age 6, single men, single women), we do not. Instead, we include family type as an independent variable.
25 An additional category was added to the tenure variable in order to capture those in public housing or subsidized housing. The CE program has kept public housing and subsidized housing as separate categories in its imputations.
26 We use the state of residence if a value for it is provided and a dummy variable if the state is missing from the data.
27 In this comparison, we use the mean of the five implicates as our income variable. Results are similar when we use any of the individual implicates.
28 To obtain our de-meaned estimates, we divided the Gini coefficient in a given year by the mean of the Gini coefficients over the entire study period. Presenting de-meaned values allows us to focus on changes from the mean and permits a clearer illustration of observed trends.
29 AVBs are excluded from this exercise because they have no income to be imputed.
30 The CE program conducts its own comparison to the CPS. See “Measuring the impact of income imputation in the Consumer Expenditure Survey: a multi-year comparison of income data with estimates from the Current Population Survey,” report 1021 (U.S. Bureau of Labor Statistics, Consumer Expenditure Survey, 2006–2007), pp. 10–19, https://www.bls.gov/cex/twoyear/200607/csxcps.pdf.
31 See Bruce Meyer and James Sullivan, “Consumption and income inequality and the Great Recession,” American Economic Review 103, no. 3, 2013, pp. 178–183. See also Jonathan Heathcote, Fabrizio Perri, and Giovanni Violante, “Unequal we stand: an empirical analysis of economic inequality in the US, 1967–2006,” Review of Economic Dynamics 13, no. 1, 2010, pp. 15–51.