
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
This is an archived page. To see the latest version, please visit Consumer Expenditures and Income: Calculation.
The use of Consumer Expenditure Survey’s (CE) sample data to estimate population quantities of interest, such as the average expenditure per consumer unit on a particular item category, is achieved through the use of weights. Each consumer unit in the survey is assigned a weight that is the number of similar consumer units in the U.S. civilian noninstitutional population the sampled consumer unit represents. Using these weights, the average expenditure per consumer unit on a particular item category is estimated with the standard weighted average formula:
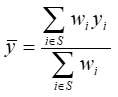
where
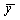 = the average expenditure per consumer unit on the item category,
= the average expenditure per consumer unit on the item category,
yi= the expenditure made by the i th consumer unit on the item category,
wi= the weight of the i th consumer unit in the sample, and
S = the sample of consumer units that participated in the survey.
For example, if yi is the expenditure on eggs made by the i th consumer unit in the sample during a given time period, then is an estimate of the average expenditure on eggs made by all consumer units in the U.S. civilian noninstitutional population during that period.
If one wants to estimate the proportion of consumer units that purchased eggs during a given period, then the same formula is applied, where yi is set equal to 1 if the i th consumer unit purchased eggs during the time period, and 0 if it did not. When this binary definition of yi is used, is an estimate of the proportion of all consumer units in the U.S. civilian noninstitutional population that purchased eggs during the given period.
Several factors are involved in computing the weight of each consumer unit from which a usable interview is received. Each consumer unit is initially assigned a base weight equal to the inverse of the consumer unit’s probability of being selected for the sample. The total U.S. target population counts for these base weights come from the Census Current Population Survey. Base weights in the CE are typically around 10,000, which means a consumer unit in the sample represents 10,000 consumer units in the U.S. civilian noninstitutional population?itself plus 9,999 other consumer units that were not selected for the sample. The base weight is then adjusted by the following factors to correct for certain nonsampling errors:
Weighting control factor. This adjusts for subsampling in the field. Subsampling occurs when a data collector visits a particular address and discovers multiple housing units where only one housing unit was expected.
Noninterview adjustment factor. This adjusts for interviews that cannot be conducted in occupied housing units due to a consumer unit’s refusal to participate in the survey or the inability to contact anyone at the housing unit in spite of repeated attempts. This adjustment is based on region of the country, consumer unit size, number of contact attempts, and the average adjusted gross income in the consumer unit’s zip code according to a publicly available database from the Internal Revenue Service.
Calibration factor. This adjusts the weights to 24 “known” population counts to account for frame undercoverage. These known population counts are for age, race, household tenure (owner or renter), region of the country, and urban or rural. The population counts are updated quarterly using the Current Population Survey estimates. Each consumer unit is given its own unique calibration factor. There are infinitely many sets of calibration factors that can make the weights add up to the 24 known population counts, and the CE uses nonlinear programming to select the set that minimizes the amount of change made to the “initial weights” (initial weight = base weight x weighting control factor x noninterview adjustment factor).
After adjusting the base weights by these factors, the final weights are typically around 17,000, which means an interviewed consumer unit represents 17,000 consumer units in the U.S. civilian noninstitutional population?itself plus 16,999 other consumer units that did not participate in the survey.
The precision of the estimator is measured by its standard error. Standard errors measure the sampling variability of the CE estimates. That is, standard errors measure the uncertainty in the survey estimates caused by the fact that a random sample of consumer units from across the United States is used instead of every consumer unit in the nation. See table 2.
The CE’s standard errors are estimated by using the method of “balanced repeated replication.” In this method, the sampled PSUs are divided into 43 groups (called strata), and the consumer units within each stratum are randomly divided into two half samples. Half of the consumer units are assigned to one half sample, and the other half are assigned to the other half sample. Then 44 different estimates of are created using data from only one half sample per stratum. There are many combinations of half samples that can be used to create these replicate estimates, and the CE uses 44 of them that are created in a “balanced” way with a 44x44 Hadamard matrix. The standard error of is then estimated by:
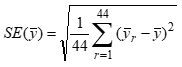
where
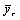 is the r th replicate estimate of .
is the r th replicate estimate of .
The coefficient of variation is a related measure of sampling variability that measures the variability of the survey estimate relative to the mean. It is defined by the equation:
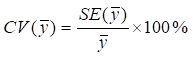 .
.
| Item category | Average annual expenditure per consumer | Standard error, SE(y¯) | Coefficient of variation, CV (y¯) (in percent) |
|---|---|---|---|
| Total expenditures | $51,100 | $520 | 1.02 |
| Food | 6,602 | 100 | 1.51 |
| Housing | 17,148 | 171 | 1 |
| Apparel | 1,604 | 36 | 2.26 |
| Transportation | 9,004 | 148 | 1.64 |
| Healthcare | 3,631 | 53 | 1.47 |
| Entertainment | 2,482 | 49 | 1.98 |
| Personal care | 608 | 15 | 2.46 |
| Cash contributions | 1,834 | 97 | 5.29 |
| Personal insurance and pensions | 5,528 | 116 | 2.09 |
| Other | 2,659 | 59 | 2.21 |
| Source: U.S. Bureau of Labor Statistics. | |||