
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
The Current Employment Statistics (CES) sample is a stratified, simple random sample of worksites, clustered by unemployment insurance (UI) account number. The UI account number is an identifier on the Bureau of Labor Statistics longitudinal database (LDB), the collection of employer records that serves as the sampling frame for CES employment estimates. The sample strata, or subpopulations, are defined by state, industry, and employment size, yielding a state-based design. Sampling rates for each stratum are determined through a method known as optimum allocation, which distributes a fixed number of sample units across a set of strata to minimize the overall variance, or sampling error, on the primary estimate of interest. The total nonfarm employment level is the primary estimate of interest, and the CES sample design gives top priority to measuring it as precisely as possible, thereby minimizing the statistical error around the statewide total nonfarm employment estimates. The CES-State and Area (CES-SA) program uses the same sample and collection methods, thus references to CES apply to both CES-N and CES-SA programs.
The longitudinal database (LDB) of employer records is the universe from which CES draws the establishment survey sample. The LDB contains data on millions of business establishments and state and local governments covered by UI and representing nearly all elements of the U.S. economy. The Quarterly Census of Employment and Wages (QCEW) program collects these data from employers on a quarterly basis in cooperation with labor market information agencies (LMIs). The LDB, which is made from the QCEW, contains employment and wage information from employers, as well as name, address, and location information. It also contains identification information such as UI account number and reporting unit or worksite numbers.
The LDB contains records of all employers covered under the UI tax system in each state and covers about 97 percent of all employment within the scope of CES. Because UI laws can vary by state, some types of workers are not covered by UI, and are not counted by the QCEW. Some, but not all, noncovered workers are within the scope of CES. For example, CES includes employees of railroads and religious organizations, elected officials, and student workers, who are typically not covered by UI. Data for employers are generally reported at the worksite level. Employers with multiple establishments within a state usually report data for each worksite. The LDB tracks establishments over time and links them from quarter to quarter.
The total private and government portions of the CES sample are selected using two different methods. Private establishments in the CES sample frame are stratified by state, industry, and size. Stratification groups population members together for the purpose of sample allocation and selection. The strata, or groups, are composed of homogeneous units, with 13 industries (mining and logging, construction, manufacturing, wholesale trade, retail trade, transportation and warehousing, utilities, information, financial activities, professional and business services, private education and health services, leisure and hospitality, and other services) and 8 size classes, resulting in 104 allocation cells per state. (See exhibit 1.)
| Size Class | Number of employees |
|---|---|
| 1 | 0–9 employees |
| 2 | 10–19 employees |
| 3 | 20–49 employees |
| 4 | 50–99 employees |
| 5 | 100–249 employees |
| 6 | 250–499 employees |
| 7 | 500–999 employees |
| 8 | 1000+ employees |
The sampling rate for each stratum is determined through a method known as optimum allocation. Optimum allocation minimizes variance at a fixed cost or minimizes cost for a fixed variance. Under the CES probability design, a fixed number of sample units for each state is distributed across the allocation strata in such a way as to minimize the overall variance, or sampling error, of the over-the-month change for total state employment. The number of sample units in the CES probability sample are fixed according to available program resources and are reviewed and updated every 5 years to realign survey resources with employment changes in each state, while maintaining a certain level of accuracy in each state. The optimum allocation formula, using Neyman's allocation, places additional sample in strata with greater variance and more units.
Some units, called certainty units, are always asked to be a part of the sample. These units, assigned weight of 1 to represent only themselves, must meet at least one of the following conditions:
The CES government sample is not part of the program's probability-based design. CES is able to achieve a very high level of universe employment coverage in government by obtaining full payroll employment counts for many government agencies, eliminating the need for a probability-based sample design. Government estimates are summed with the total private estimates to obtain estimates of total nonfarm employment.
Updated universe files provide the most recent information about industry, size, and metropolitan area designation. The CES program draws a sample each year from the first quarter LDB data when it becomes available later in the year. Annual sample selection helps keep the CES survey current with respect to employment from business births and business deaths. An additional birth update is drawn from the third quarter LDB when it becomes available the next year.
The sampling frame is separated into allocation cells after all out-of-scope records are removed. Units in each allocation cell are grouped by metropolitan statistical area (MSA) sorted by the number of UI accounts in each MSA. As the sampling rate is uniform across the entire allocation cell, implicit stratification by MSA ensures that a proportional number of units are sampled from each MSA. Some MSAs may have too few UI accounts in the allocation cell; these MSAs are combined and treated as a single MSA.
Permanent random numbers (PRNs) are assigned to all UI accounts on the sampling frame. As new units appear on the frame, random numbers are also assigned to those units through a process called collocation. The PRN carries forward as records are linked across time. All units within each selection cell are sorted by PRN and are selected according to the specified sample selection rate. The number of units selected randomly from each selection cell is equal to the product of the sample selection rate and the number of eligible units in the cell plus any carryover from the prior selection cell. The result is rounded to the nearest whole number. Carryover is defined as the amount that is rounded up or down to the nearest whole number.
Collocation of new birth units occurs every quarter with the update of the CES frame. CES assigns each birth unit a random number and then ranks each unit within each stratum by that random number. The following formula ensures that the new units have equal distances between each other within a strata in an order based on their rank, shown in equation 1.
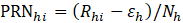
where
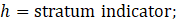
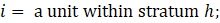
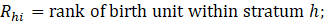
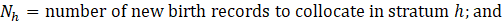
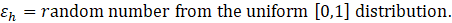
All units remain in the sample for a minimum of 2 years because of the added cost and workload associated with enrolling new sample units. A "swapping" procedure ensures that all units meet this minimum requirement. The procedure allows units to be swapped into the sample that were newly selected during the previous sample year and not reselected as part of the current probability sample. The procedure removes a unit within the same selection cell and places the newly selected unit from the previous year back into the sample. To reduce respondent burden, a similar procedure swap units out of the sample that have been sample members for 4 or more consecutive years. The swap-out procedure removes an established sample unit from its selection cell and replaces it with a new unit in the same selection cell. In order to maintain an implicit, proportional allocation across MSAs in the same strata, the ideal unit swap would occur within the same stratum and MSA. On rare occasions, a swap may involve a unit from a different MSA, but the stratum must remain the same. If a unit has been identified for swapping, and there are no units available in the same stratum, then the swap will not take place. Approximately 66 percent of the CES sample for private industries overlaps from the previous sample to the current sample.
Once the sample is drawn, sample selection weights are calculated based on the number of UI accounts actually selected within each allocation cell. The sample selection weight is approximately equal to the inverse of the probability of selection, or the inverse of the sampling rate, shown in equation 2.
where
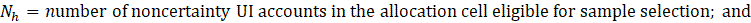
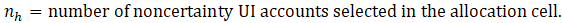
Sample units that are reporting for anything other than the sample unit are reviewed for reweighting. This can happen when a unit merges with another UI account after the sample selection. If two units, A and B, are from different strata, CES uses the following formula to assign the merged weight.
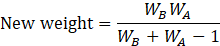
where
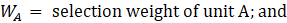
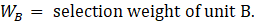
The weight is designed to always be the inverse of the probability of selection, but when the two units are from the same strata, their probability of selection is dependent on the other unit being selected. The general formula is below:
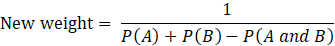
where
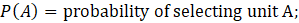
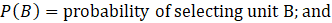
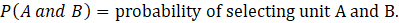
Because of the dynamic nature of the economy, there is a constant cycle of business openings (births) and closings (deaths). A sample update is performed during the summer each year, drawing from the previous year's third quarter LDB data. This update selects and includes newly opened units and other units not previously eligible on the frame. Location, contact, and administrative information are updated for all establishments that were selected as part of the sample updates.
The coverage section of the technical note to the CES Benchmark Article shows the latest benchmark employment levels for total nonfarm and major industry sections and the approximate proportion of total universe employment coverage. Table 1 shows March 2025 shows the latest benchmark employment levels for total nonfarm and major industry sectors and the approximate proportion of total universe employment coverage. The coverage for individual industries within each sector may vary from the proportions shown.
The CES program uses a probability-based sample to estimate employment for all private industries. Sample distribution by industry reflects the goal of minimizing sampling error in total nonfarm employment estimates, while also providing reliable employment estimates by industry. Sample coverage rates vary by industry as a result of building a design to meet these goals. Some differences in each industry s sample size and coverage stem from average firm size. These differences do not cause bias in the CES employment estimates because the use of industry sampling strata and sampling weights ensure that each firm is represented in the estimates.
The CES program achieves a high level of universe coverage in its government sample so a probability-based sample design is not necessary. The coverage rate ensures a high degree of reliability for government employment estimates. Private sector and government employment estimates are summed to get total nonfarm employment. Since the CES program uses government sample to estimate only government estimates, it does not bias the total nonfarm employment estimates.
The employment universe for private-sector employment that the CES sample is estimating is highly skewed, as shown in the total private universe employment by size of UI table. The largest UI accounts (those with 1,000 employees or more) comprise less than 1 percent of all UI accounts but contain approximately nearly a third of total private employment. The smallest size class (0 9 employees) contains nearly three quarters of all UIs and about a tenth of total private employment. CES samples larger firms at a higher rate than smaller firms, a standard technique commonly used in business establishment surveys.
A much greater proportion of large UIs are selected for the CES survey; however, that does not create a bias in either the sample or the estimates. The total private CES sample employment by size of UI table shows the distribution of the active CES sample units by employment size. Each sample unit selected is assigned a weight based on its probability of selection, ensuring that all firms of its size are properly represented in the estimates. For example, if 1 in every 100 firms are selected from UIs in the smallest firm stratum, they are assigned a weight of 100 because they represent themselves and 99 other firms that were not sampled. The use of sample weights in the estimation process prevents a large- or small-firm bias in the estimates.