
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.

Crossref 0
Hedonic price indexes under static pricing: an application to PPI microprocessors, Business Economics, 2025.
Cloud computing services (hosting) is an important component of the Producer Price Index (PPI) for data processing, hosting, and related services. The current approach to changes in cloud services is to estimate a price change between the old and new service that is equal to the average of price changes for similar products in the PPI. This method has limitations because it does not specifically account for changes to characteristics such as microprocessor, memory, and data storage, which are key price-determining characteristics that see rapid technological change. In order to estimate price changes more accurately in this ever-evolving industry, we develop time dummy hedonic models. Our models use publicly available data while future BLS models could instead use confidential respondent data for their estimates. One of the challenges of developing models is accounting for the performance of the microprocessors used in the cloud services. One of the cloud service providers in our dataset has a performance benchmark for their cloud services. We calculate models that use this benchmark and compare them to models that use the characteristics of the microprocessors in order to evaluate the appropriateness of using microprocessor characteristics as explanatory variables in future models. The comparison between these two types of models is critical, because none of the other service providers currently has a microprocessor benchmark. We also use a statistical learning technique to select variables for our models. Finally, we discuss the feasibility of applying these models to the PPI in the future.
Cloud computing is a key information technology service with high and growing revenue. Worldwide, end-user spending on public cloud services was projected to grow 23.1 percent, from $270 billion in 2020 to $332.3 billion in 2021, and it was forecast to increase to $397.5 billion in 2022.1 Furthermore, cloud services are projected to make up 14.2 percent of total information technology (IT) spending worldwide by 2024, up from 9.1 percent of spending in 2020.2 Like many high-tech goods and services, cloud computing has experienced strong revenue growth while also undergoing rapid technological improvement. This improvement, also known as quality change, needs to be accounted for when measuring the rate of price change over time.
The U.S. Bureau of Labor Statistics’ (BLS) Producer Price Index (PPI) tracks only “pure” price change, which is price change that excludes changes in quality. When a product or service does change, there are methods, known as quality adjustment (QA), which can account for this change.3
One of the QA methods is hedonic QA. This method uses a hedonic regression model to estimate and control for changes in quality in order to give a measure of pure price change.
For this article, we use data from three of the top cloud providers to develop a hedonic model for cloud computing services.4 We cover the following: (1) cloud computing industry, index, and technological background; (2) data and methodology for the hedonic models; (3) construction of the model; and (4) the results of the model with comparisons to existing methodology.
The PPI program surveys establishments in data processing, hosting, and related services (North American Industry Classification System (NAICS) code 518210) that provide infrastructure or support for hosting or data processing purposes. The establishments are often third-party service providers for other businesses and governments who outsource their business processes, data, or computing services. These outsourced services are provided by equipment owned, operated, and held by the establishments within the data processing and cloud industry. This industry is highly concentrated, and the very large providers have the greatest influence over the market prices for cloud services.
In 2018, Amazon Web Services (AWS) led the cloud computing industry with ownership of nearly half of the infrastructure as a service (IaaS) market (47.8 percent). The other leaders in the industry were Microsoft (15.5 percent), Alibaba (7.7 percent), Google (4.0 percent), and IBM (1.8 percent).5 As leaders in the industry, their pricing structures are similar. AWS, Microsoft Azure, and Google all have customizable on-demand packaging as well as prestructured packages that are comparable. For these reasons we have chosen to build our data sample using these three service providers.
Traditionally, data and computing services and business processes have been completed onsite by the businesses using them. For instance, data management and payroll used servers and computers located in the same building where a business conducted its primary activities. However, with the emergence of the data processing service industry, businesses are now able to rent data storage space and computing power from offsite servers.
There are several major benefits to outsourcing these services. First, businesses no longer have to purchase and maintain complicated and expensive IT equipment. Another benefit is that the services provided are often sold in an on-demand, customizable fashion. As companies’ computing needs change, they can vary the capacity of data processing services they purchase, which can reduce costs. If the companies were to host data processing services in-house, they would need to have computing resources available to handle peak demand that would otherwise sit idle most of the time.
Within the PPI program’s structure, data processing, hosting, and related services is an aggregate index that contains lower level indexes. These lower level indexes are differentiated by the types of services provided: business process management services; data management, information transformation, and related services; hosting, application service provision (ASP), and other IT infrastructure provisioning services. Cloud computing is the provisioning of virtual computer infrastructure which is classified in the hosting, ASP, and other IT infrastructure provisioning services lower level index.
Cloud computing can be classified into three areas: software as a service, platform as a service, and infrastructure as a service. Software as a service (SaaS) is the most fully featured and easily accessible cloud computing package. With SaaS, there is no need for a customer to install, manage, or purchase software. The customer simply connects to the cloud provider and uses the software. As SaaS provides a finished product, SaaS products are not classified with the remaining services, but rather in software publishing (NAICS 511210). Platform as a service (PaaS) has a much broader structure compared with SaaS packages. As its title suggests, PaaS provides a platform on which developers can build and attach their own applications. These platforms are typically made up of an operating system (OS), a programming language and an environment for it, a database, and a web server. Finally, the service this article will focus on, infrastructure as a service (IaaS), is the most basic type of cloud computing. Each package is essentially a virtual version of a blank computer: microprocessor, memory, storage, etc. Furthermore, these packages often include access to a basic OS, such as a limited version of Linux, or the option to purchase access to a different OS, such as Windows.
We chose to focus on IaaS packages for the PPI’s QA model because, as the broadest service offering, IaaS is typically used as a base on which other services are built. For instance, SaaS and PaaS both use the computer resources that are offered through IaaS. By developing a model for IaaS, we are also able to describe many of the factors that affect the price for SaaS and PaaS.
BLS determines the current pricing method for IaaS in the PPI by both the service characteristics and transaction terms for each item. For IaaS, the main types of prices are fee-based transaction prices (average rates, standard rates, or prepaid rates) or estimated flat fees. Flat fees are more commonly seen in contracts with large firms. These contracts are negotiated on the basis of an average or expected sum of cloud usage per month. However, cloud usage is often so variable that the real value of these contracts is almost never the same from month to month. Fee-based transaction prices have become much more common in the cloud computing industry because the industry has shifted toward on-demand services to cater to small businesses, individual consumers, and large companies simultaneously. To control for variability of usage, we focus on per-hour pricing in IaaS packages as the dependent variable of our model.
The service characteristics of an IaaS package are the variable features in our model, and the combinations of these features determine the price, either as a contract or a sum-of-its-parts, fee-based transaction.6
The combination of characteristics that a customer may choose to purchase is highly customizable and designed to fit the needs of any customer, including independent users, small businesses, and large corporations. Although access to cloud services has become more convenient over time, this flexibility has made pricing more complicated. This complexity is why we have developed this model. Having a hedonic model will allow us to separate changes in the quality of the cloud service from changes in the price.
Several of these characteristics can be offered as stand-alone services or products that have substantial impact on IaaS pricing and quality. We include storage as a characteristic because cloud service providers typically provide a small amount of storage with IaaS. They also sell stand-alone storage, but we do not include that in our datasets or models. Microprocessor hardware is also included as a price-determining characteristic because the generation and model of a microprocessor can cause quality changes for cloud packages that may seem unchanged at face value. For instance, Diane Coyle and David Nguyen note the speed and changes in AWS packages between generations.7 In November 2017, AWS claimed the new IaaS Elastic Compute Cloud (EC2) M5 instances would provide a 14-percent performance improvement over the previous M4 generation instances without a change in price. The only change announced between the two generations was an upgrade to a more modern microprocessor.
There are also several characteristics that can have an impact on price that are not quantifiable using publicly available data and so are not a focus of this model. For example, prices often differ by region because a higher concentration of larger data distribution centers in an area as well as the proximity of data distribution centers to the consumer influence speed and performance of cloud services. This effect is referred to as latency. However, because cloud services are available to the consumer from anywhere, we have no way of knowing to what degree latency impacts overall instance performance. Likewise, there is no way for us to know how much consumers use these products over a certain timeframe, so we chose to focus on time-based fees, specifically per hour costs of each instance.
Hedonic regression models provide a way to quality adjust services. The basic form of the hedonic models is a linear regression with the natural logarithm of price per hour as the dependent variable and characteristics of the service as the explanatory variables. The explanatory variables represent the different attributes that the service comprises, and the coefficients on those variables (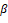 ) represent the cost of those attributes. The services are indexed by
) represent the cost of those attributes. The services are indexed by 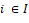 and each service
and each service 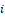 has characteristics
has characteristics 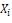 . Thus, the form of a hedonic model is:
. Thus, the form of a hedonic model is:
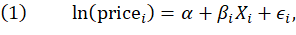
where 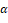 is the intercept term and
is the intercept term and 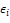 is the error term.
is the error term.
Previous work in applying hedonics to cloud computing exists. In 2016, Liang Zhang constructed a dataset for AWS and estimated hedonic models for the 2009–15 period.8 Those models were assessed on both multiple periods (time dummy method) and single periods (adjacent period method) to estimate quality adjusted measures of price change for AWS cloud services. Mitropoulou et al. also applied hedonics to cloud computing.9 They assembled a dataset of 25 cloud service providers and estimated a hedonic model for a single period. Coyle and Nguyen computed AWS prices per EC2 Compute Unit (ECU) and compared them to a nominal price index per product class, using the EC2 “large” and “x.large” instances available in the United Kingdom from the first quarter of 2010 to the third quarter of 2018.10
For the models in this article, we use the time dummy hedonic method. This method takes equation (1) and adds a time index, t, and a time dummy 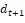 that indicates whether a service is from the first period or the second period. In this case, the time dummy model is:
that indicates whether a service is from the first period or the second period. In this case, the time dummy model is:
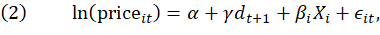
where  is the coefficient associated with the time dummy.
is the coefficient associated with the time dummy.
The methodology we use is drawn from the methodology of David Byrne, Carol Corrado, and Daniel Sichel.11 We use time dummy hedonic models because they allow us to calculate price changes that occur from changes to several interrelated characteristics without having the proportions of overall sales dedicated to each instance variation. Revenue and sales information at the product level are not often released to the public.
Because we use time dummy models, the dataset consists of two or more periods of data. Specifically, we use overlapping two-quarter datasets. For example, the dataset for the first model consists of the second quarter and third quarter of 2017 and the dataset for the second model consists of the third quarter and fourth quarter of 2017.
With differences in characteristics being accounted for by the other explanatory variables, the time dummy variable gives the quality adjusted price change between the two quarters.12
The model is intended to be used to directly estimate quality adjusted price change. Typically, a producer price index comprises items that represent specific services and their associated prices. In this case, items represent the aggregation of services included in the dataset used in the model. The item prices are being used to show quality adjusted price change calculated from the model.
The dataset is assembled to back test QA models. It includes quarterly observations from the second quarter of 2017 through the second quarter of 2019 for three of the largest services in the industry: AWS, Google Cloud, and Microsoft Azure.
The selection of characteristics to include in the model is important because it helps determine the magnitude of the time dummy coefficient. One of the key drivers of quality change with cloud services is the microprocessor used in the servers. Microprocessors undergo continual quality changes, and these changes are responsible for improvements in a range of high-tech goods and services, from smartphones to artificial intelligence. Each cloud provider uses a limited number of microprocessor models in their servers. This limited number of models makes it difficult to have enough variation in microprocessor characteristics for the model to estimate significant coefficients.
AWS has a measure of the performance of the microprocessor used in their Elastic Compute Cloud (EC2) service called EC2 Compute Unit (ECU).13 Because ECU is available for all AWS cloud services and it is calculated by AWS itself, ECU is a credible gauge of microprocessor performance. Neither Microsoft Azure nor Google Cloud have a microprocessor measure like AWS’ ECU. Byrne, Corrado, and Sichel used AWS ECU in their models, and we emulate this approach.14
There are also third-party microprocessor benchmarks, such as the Standard Performance Evaluation Corporation central processing unit (CPU) and PassMark CPU benchmarks, but both of these only have results for a limited number of microprocessors used in cloud services. This limited number of results is too small to support a hedonic model.
Fortunately, characteristics information is available for all microprocessors. However, microprocessors are complicated devices, and selecting the characteristics to include in the model is challenging for two reasons.15 First, only a few different microprocessors are used by any one cloud service provider, which limits the number of microprocessor characteristics our model can support. As described by Steven Sawyer and Alvin So, the main characteristics of microprocessors are cores, threads, thermal design power (TDP), base frequency, turbo frequency, and cache.16
Second, cloud services are priced by virtual CPU (vCPU). Each vCPU corresponds to a microprocessor thread. Consequently, each vCPU only uses part of the microprocessor cache and accounts for part of the TDP. As such, for use in our models, the cache and TDP variables have to be multiplied by the proportion of threads used by each individual cloud computing service to the total threads in the microprocessor. For example, if a cloud computing service instance offers two vCPUs and the microprocessor used to provide the service has 10 threads, 8 MB of cache, and a TDP of 100 watts, then the cloud service uses 1.6 MB of cache and accounts for 20 watts of TDP. In this example, the remaining 8 threads, 6.4 MB of cache, and 80 watts of TDP would remain available to run other cloud computing service instances. Base and turbo frequency are the same throughout the microprocessor, and so they do not need to be adjusted.
In 2018, Sawyer and So used statistical learning techniques to select specifications for microprocessor hedonic models.17 These techniques, in turn, were taken from An Introduction to Statistical Learning.18 Because many of the price-determining characteristics for cloud computing services are the same as for microprocessors, we applied the same statistical learning techniques that Sawyer and So use for their hedonic model of microprocessors.
The technique starts with prescreening the data. Our dataset for AWS has seven variables (not including the time dummy variables). We start with calculating the residual sum of squares (RSS) for each single-regressor model. The single-regressor model with the lowest RSS is selected as a prescreened model. We then repeat the procedure for every two-regressor model. The two-regressor model with the lowest RSS is selected as a prescreened model. We continue this process, increasing the number of regressors by one each time, until we have seven prescreened models. To select the best model from the prescreened models, we use repeated k-fold cross validation.19
Repeated k-fold cross validation evaluates the performance of a model by the model’s ability to accurately predict the prices (the dependent variable of the model) in the dataset. With time dummy hedonics, we are most interested in the time dummy variable (an explanatory variable) because that variable determines the rate of price change. Though there is a seeming mismatch between what the statistical learning technique and time dummy hedonics focus on, the technique’s purpose is to prevent the selection of an overfitted model. As demonstrated in a previous article, the variables included in a model affect the magnitude of the time dummy.20 For this reason, we think it makes sense to use the previously mentioned statistical learning technique with time dummy hedonic models.
Using the methodology detailed in the previous section, we developed cloud services hedonic models for the major producers in the industry. We first estimated models for AWS using ECU to represent microprocessor performance. The results are in tables 1 and 2. Please note that all the models in this article use the time dummy method, have the natural logarithm of price as the dependent variable, and use two adjacent quarters of data.
Only models that contained quarters with exiting or entering services had price change. However, we also run the statistical learning technique on the quarters with no exit or entry to show the stability of the service characteristic coefficients. The specific form of the model evaluated by the statistical learning technique is:
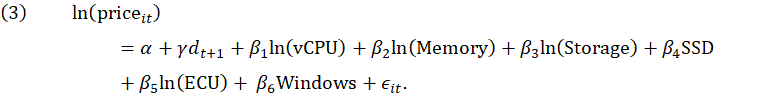
| Variable | Q2 2017–Q3 2017 | Q3 2017–Q4 2017 | Q4 2017–Q1 2018 | Q1 2018–Q2 2018 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0000 | -0.0296 | 0.0000 |
| Standard error | 0.0455 | 0.0455 | 0.0435 | 0.0372 |
| Ln(vCPU) | -1.60941 | -1.60941 | 2 | 2 |
| Standard error | 0.4586 | 0.4586 | 2 | 2 |
| Ln(Memory) | 0.70511 | 0.70511 | 0.53791 | 0.53761 |
| Standard error | 0.0792 | 0.0792 | 0.0446 | 0.0423 |
| Ln(Storage) | 0.14011 | 0.14011 | 0.16081 | 0.15881 |
| Standard error | 0.0224 | 0.0224 | 0.0229 | 0.0232 |
| SSD | -1.19391 | -1.19391 | -1.28731 | -1.25061 |
| Standard error | 0.1830 | 0.1830 | 0.1911 | 0.1931 |
| Ln(ECU) | 1.93271 | 1.93271 | 0.44071 | 0.44541 |
| Standard error | 0.4124 | 0.4124 | 0.0511 | 0.0468 |
| Windows | 0.46761 | 0.46761 | 0.50471 | 0.53181 |
| Standard error | 0.0455 | 0.0455 | 0.0415 | 0.0372 |
| Observations | 128 | 128 | 152 | 176 |
| Adjusted R-squared | 0.9650 | 0.9650 | 0.9659 | 0.9683 |
| 1 Statistically significant at the 5-percent level. 2 Omitted from model. Note: AWS = Amazon Web Services; ECU = elastic compute cloud compute unit; Ln = natural logarithm; SSD = solid-state drive; vCPU = virtual central processing unit; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2018–Q3 2018 | Q3 2018–Q4 2018 | Q4 2018–Q1 2019 | Q1 2019–Q2 2019 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0671 | 0.0000 | 0.0000 |
| Standard error | 0.0372 | 0.0478 | 0.0479 | 0.0479 |
| Ln(vCPU) | 2 | 1.02761 | 1.31021 | 1.31021 |
| Standard error | 2 | 0.2099 | 0.1659 | 0.1659 |
| Ln(Memory) | 0.53761 | 0.44271 | 0.4521 | 0.4521 |
| Standard error | 0.0423 | 0.0436 | 0.0360 | 0.0360 |
| Ln(Storage) | 0.15881 | 0.10861 | 0.06341 | 0.06341 |
| Standard error | 0.0232 | 0.0238 | 0.0244 | 0.0244 |
| SSD | -1.25061 | -0.86621 | -0.54491 | -0.54491 |
| Standard error | 0.1931 | 0.1801 | 0.1687 | 0.1687 |
| Ln(ECU) | 0.44541 | -0.50071 | -0.79081 | -0.79081 |
| Standard error | 0.0468 | 0.2005 | 0.1709 | 0.1709 |
| Windows | 0.53181 | 0.51831 | 0.50831 | 0.50831 |
| Standard error | 0.0372 | 0.0457 | 0.0479 | 0.0479 |
| Observations | 176 | 206 | 236 | 236 |
| Adjusted R-squared | 0.9683 | 0.9466 | 0.9349 | 0.9349 |
| 1 Statistically significant at the 5-percent level. 2 Omitted from model. Note: AWS = Amazon Web Services; ECU = elastic compute cloud compute unit; Ln = natural logarithm; SSD = solid-state drive; vCPU = virtual central processing unit; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
Only the models for the fourth quarter of 2017 to the first quarter of 2018 and the third quarter of 2018 to the fourth quarter of 2018 had price changes. Some of the variables have counterintuitive signs on their coefficients in some of the models, such as those of the natural logarithm of ECU in the last three models.21 However, with time dummy models, we are mainly interested in the time dummy coefficient.
Even though few variables are being eliminated, there is still value in using the statistical learning specification algorithm. For instance, the natural logarithm of vCPU is not selected for three of the models, and this variable is one of the main price-determining characteristics. Without the statistical learning specification algorithm, we would have not known that omitting the natural logarithm of vCPU would produce better performance in those three models.
We also estimate models for AWS using microprocessor characteristics instead of ECU. The ECU models serve as a benchmark for the performance of the microprocessor characteristics models. This comparison will be useful for gauging the appropriateness of using microprocessor characteristics in the Microsoft Azure and Google Cloud models where an ECU-like variable is not available.
For the models using microprocessors characteristics, the vCPU variable is omitted because it is strongly correlated with cache and TDP. As explained previously, the amount of cache or TDP is proportional to the number of vCPUs. Because the base and turbo frequency variables are closely correlated and there are so few microprocessors in the data set, the model selection technique was done twice, once using base frequency and omitting turbo frequency and once using turbo frequency and omitting base frequency. The specific form of the model evaluated by the statistical learning technique is:
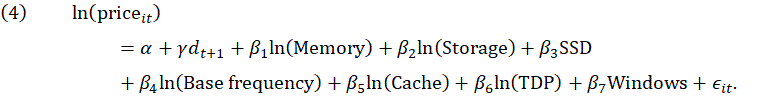
| Variable | Q2 2017–Q3 2017 | Q3 2017–Q4 2017 | Q4 2017–Q1 2018 | Q1 2018–Q2 2018 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0000 | -0.0358 | 0.0000 |
| Standard error | 0.0338 | 0.0338 | 0.0368 | 0.0305 |
| Ln(Memory) | 0.9991 | 0.9991 | 0.82481 | 0.83021 |
| Standard error | 0.0690 | 0.0690 | 0.0597 | 0.0648 |
| Ln(Storage) | 0.0521 | 0.0521 | 0.15951 | 0.16961 |
| Standard error | 0.0285 | 0.0285 | 0.0237 | 0.0250 |
| SSD | -0.54031 | -0.54031 | -1.30281 | -1.38551 |
| Standard error | 0.2419 | 0.2419 | 0.1969 | 0.2135 |
| Ln(Base frequency) | 1.55211 | 1.55211 | 2.76591 | 3.14691 |
| Standard error | 0.3745 | 0.3745 | 0.2894 | 0.4642 |
| Ln(Cache) | -2.5031 | -2.5031 | 0.13271 | 0.43231 |
| Standard error | 0.3498 | 0.3498 | 0.0598 | 0.1015 |
| Ln(TDP) | 2.47081 | 2.47081 | 2 | -0.30151 |
| Standard error | 0.3265 | 0.3265 | 2 | 0.1429 |
| Windows | 0.46761 | 0.46761 | 0.50471 | 0.53181 |
| Standard error | 0.0338 | 0.0338 | 0.0345 | 0.0305 |
| Observations | 128 | 128 | 152 | 176 |
| Adjusted R-squared | 0.9807 | 0.9807 | 0.9764 | 0.9786 |
| 1 Statistically significant at the 5-percent level. 2 Omitted from model. Note: AWS = Amazon Web Services; CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2018–Q3 2018 | Q3 2018–Q4 2018 | Q4 2018–Q1 2019 | Q1 2019–Q2 2019 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0708 | 0.0000 | 0.0000 |
| Standard error | 0.0305 | 0.0431 | 0.0456 | 0.0456 |
| Ln(Memory) | 0.83021 | 0.73991 | 0.70521 | 0.70521 |
| Standard error | 0.0648 | 0.0570 | 0.0542 | 0.0542 |
| Ln(Storage) | 0.16961 | 0.10661 | 0.05981 | 0.05981 |
| Standard error | 0.0250 | 0.0229 | 0.0231 | 0.0231 |
| SSD | -1.38551 | -0.90081 | -0.56041 | -0.56041 |
| Standard error | 0.2135 | 0.1753 | 0.1591 | 0.1591 |
| Ln(Base frequency) | 3.14691 | 2.58981 | 2.19971 | 2.19971 |
| Standard error | 0.4642 | 0.4648 | 0.4955 | 0.4955 |
| Ln(Cache) | 0.43231 | 0.68011 | 0.79811 | 0.79811 |
| Standard error | 0.1015 | 0.1401 | 0.1412 | 0.1412 |
| Ln(TDP) | -0.30151 | -0.42621 | -0.48571 | -0.48571 |
| Standard error | 0.1429 | 0.1717 | 0.1777 | 0.1777 |
| Windows | 0.53181 | 0.51831 | 0.50831 | 0.50831 |
| Standard error | 0.0305 | 0.0423 | 0.0456 | 0.0456 |
| Observations | 176 | 206 | 236 | 236 |
| Adjusted R-squared | 0.9786 | 0.9544 | 0.9411 | 0.9411 |
| 1 Statistically significant at the 5-percent level. Note: AWS = Amazon Web Services; CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power: Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
The statistical learning technique is selecting most of the variables for the models. These models are also showing price changes from the fourth quarter of 2017 to the first quarter of 2018 and the third quarter of 2018 to the fourth quarter of 2018, just as the ECU models do. The price changes are somewhat larger in the microprocessors characteristics models, but they are not drastically different.
For the microprocessors characteristics models using turbo frequency, the specific form of the model evaluated by the statistical learning technique is:
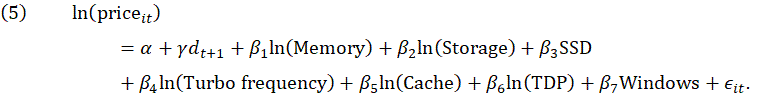
| Variable | Q2 2017–Q3 2017 | Q3 2017–Q4 2017 | Q4 2017–Q1 2018 | Q1 2018–Q2 2018 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0000 | -0.0422 | 0.0000 |
| Standard error | 0.0349 | 0.0349 | 0.0430 | 0.0340 |
| Ln(Memory) | 0.9491 | 0.9491 | 0.5961 | 0.56551 |
| Standard error | 0.0577 | 0.0577 | 0.0509 | 0.0438 |
| Ln(Storage) | 2 | 2 | 0.13411 | 0.13911 |
| Standard error | 2 | 2 | 0.0222 | 0.0227 |
| SSD | -0.13511 | -0.13511 | -1.08371 | -1.11011 |
| Standard error | 0.0499 | 0.0499 | 0.1859 | 0.1877 |
| Ln(Turbo frequency) | 2 | 2 | 2 | 2 |
| Standard error | 2 | 2 | 2 | 2 |
| Ln(Cache) | -3.40951 | -3.40951 | -0.34341 | -0.1319 |
| Standard error | 0.2746 | 0.2746 | 0.1356 | 0.0925 |
| Ln(TDP) | 3.44041 | 3.44041 | 0.71661 | 0.54071 |
| Standard error | 0.2275 | 0.2275 | 0.1059 | 0.0701 |
| Windows | 0.46761 | 0.46761 | 0.50471 | 0.53181 |
| Standard error | 0.0349 | 0.0349 | 0.0383 | 0.0340 |
| Observations | 128 | 128 | 152 | 176 |
| Adjusted R-squared | 0.9794 | 0.9794 | 0.9708 | 0.9735 |
| 1 Statistically significant at the 5-percent level. [2] Omitted from model. Note: AWS = Amazon Web Services; CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2018–Q3 2018 | Q3 2018–Q4 2018 | Q4 2018–Q1 2019 | Q1 2019–Q2 2019 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | 0.0830 | 0.0000 | 0.0000 |
| Standard error | 0.0341 | 0.0453 | 0.0460 | 0.0460 |
| Ln(Memory) | 0.53731 | 0.55161 | 0.56761 | 0.56761 |
| Standard error | 0.0345 | 0.0317 | 0.0276 | 0.0276 |
| Ln(Storage) | 0.14231 | 0.05161 | 2 | 2 |
| Standard error | 0.0229 | 0.0220 | 2 | 2 |
| SSD | -1.13751 | -0.45441 | -0.0936 | -0.0936 |
| Standard error | 0.1888 | 0.1714 | 0.0514 | 0.0514 |
| Ln(Turbo frequency) | 2 | -1.84091 | -1.97311 | -1.97311 |
| Standard error | 2 | 0.6074 | 0.5748 | 0.5748 |
| Ln(Cache) | 2 | -0.4847 | -0.3937 | -0.3937 |
| Standard error | 2 | 0.2634 | 0.2882 | 0.2882 |
| Ln(TDP) | 0.43811 | 0.9441 | 0.86121 | 0.86121 |
| Standard error | 0.0349 | 0.2557 | 0.2772 | 0.2772 |
| Windows | 0.53181 | 0.51831 | 0.50831 | 0.50831 |
| Standard error | 0.0341 | 0.0432 | 0.0460 | 0.0460 |
| Observations | 176 | 206 | 236 | 236 |
| Adjusted R-squared | 0.9733 | 0.9524 | 0.9401 | 0.9401 |
| 1 Statistically significant at the 5-percent level. [2] Omitted from model. Note: AWS = Amazon Web Services; CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
Like the characteristics models that have base frequency, the characteristics models with turbo frequency show price changes from the fourth quarter of 2017 to the first quarter of 2018 and the third quarter of 2018 to the fourth quarter of 2018. However, the characteristics models with turbo frequency show a larger deviance from the ECU models than the characteristics models with base frequency. Unlike base frequency, which was selected for all models, turbo frequency was only selected in three of the eight models. Overall, the characteristics models with base frequency show better performance than characteristics models using turbo frequency.
As of 2021, AWS no longer publishes ECU for its cloud computing services. Fortunately, as this article has shown, microprocessor characteristics can be used in place of ECU if BLS decides to use hedonic models for quality adjusting the PPI for hosting, ASP, and other IT infrastructure.
We use the same statistical learning technique to estimate models for Microsoft Azure separately for base frequency and turbo frequency. The models with base frequency take the same form as equation 4, and the models with turbo frequency take the same form as equation 5.
| Variable | Q2 2017–Q3 2017 | Q3 2017–Q4 2017 | Q4 2017–Q1 2018 | Q1 2018–Q2 2018 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | -0.0079 | 0.0095 | 0.0000 |
| Standard error | 0.0284 | 0.0279 | 0.0208 | 0.0197 |
| Ln(Memory) | 0.46461 | 0.48851 | 0.47911 | 0.43151 |
| Standard error | 0.0244 | 0.0245 | 0.0311 | 0.0155 |
| Ln(Storage) | 0.12731 | 0.11621 | 0.12311 | 0.15081 |
| Standard error | 0.0165 | 0.0165 | 0.0193 | 0.0115 |
| SSD | 0.49031 | 0.51351 | 0.51551 | 0.49181 |
| Standard error | 0.0252 | 0.0243 | 0.0259 | 0.0251 |
| Ln(Base frequency) | 2 | -0.6297 | -0.93351 | -0.79911 |
| Standard error | 2 | 0.3723 | 0.1297 | 0.1036 |
| Ln(Cache) | 0.80131 | 0.52831 | 0.40031 | 0.40391 |
| Standard error | 0.0610 | 0.1492 | 0.0262 | 0.0243 |
| Ln(TDP) | -0.37211 | -0.1176 | 2 | 2 |
| Standard error | 0.0664 | 0.1540 | 2 | 2 |
| Windows | 0.40551 | 0.4221 | 0.44361 | 0.45031 |
| Standard error | 0.0293 | 0.0280 | 0.0240 | 0.0210 |
| Observations | 136 | 148 | 150 | 140 |
| Adjusted R-squared | 0.9866 | 0.9872 | 0.9893 | 0.9919 |
| 1 Statistically significant at the 5-percent level. [2] Omitted from model. Note: CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2018–Q3 2018 | Q3 2018–Q4 2018 | Q4 2018–Q1 2019 | Q1 2019–Q2 2019 |
|---|---|---|---|---|
| Quarter dummy | 0.0295 | 0.0049 | -0.0018 | -0.0036 |
| Standard error | 0.0238 | 0.0168 | 0.0155 | 0.0157 |
| Ln(Memory) | 0.31661 | 0.26251 | 0.26311 | 0.25841 |
| Standard error | 0.0225 | 0.0098 | 0.0095 | 0.0099 |
| Ln(Storage) | 0.25691 | 0.34931 | 0.34871 | 0.35441 |
| Standard error | 0.0213 | 0.0162 | 0.0170 | 0.0171 |
| SSD | 0.26251 | 0.07851 | 0.07741 | 0.06741 |
| Standard error | 0.0316 | 0.0138 | 0.0137 | 0.0144 |
| Ln(Base frequency) | -2.91431 | -4.59421 | -4.70231 | -4.76261 |
| Standard error | 0.3972 | 0.3076 | 0.3054 | 0.3081 |
| Ln(Cache) | -0.63781 | -1.30681 | -1.34751 | -1.3791 |
| Standard error | 0.1618 | 0.0958 | 0.0933 | 0.0943 |
| Ln(TDP) | 1.06231 | 1.70111 | 1.74061 | 1.76911 |
| Standard error | 0.1607 | 0.0834 | 0.0779 | 0.0788 |
| Windows | 0.44151 | 0.45081 | 0.46831 | 0.47011 |
| Standard error | 0.0277 | 0.0170 | 0.0161 | 0.0164 |
| Observations | 132 | 138 | 152 | 152 |
| Adjusted R-squared | 0.9873 | 0.9951 | 0.9951 | 0.9949 |
| 1 Statistically significant at the 5-percent level. Note: CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2017–Q3 2017 | Q3 2017–Q4 2017 | Q4 2017–Q1 2018 | Q1 2018–Q2 2018 |
|---|---|---|---|---|
| Quarter dummy | 0.0000 | -0.0024 | 0.0050 | 0.0000 |
| Standard error | 0.0284 | 0.0283 | 0.0204 | 0.0197 |
| Ln(Memory) | 0.46461 | 0.48141 | 0.46591 | 0.43081 |
| Standard error | 0.0244 | 0.0257 | 0.0274 | 0.0157 |
| Ln(Storage) | 0.12731 | 0.11991 | 0.13071 | 0.15091 |
| Standard error | 0.0165 | 0.0171 | 0.0171 | 0.0115 |
| SSD | 0.49031 | 0.50571 | 0.50591 | 0.48941 |
| Standard error | 0.0252 | 0.0242 | 0.0263 | 0.0261 |
| Ln(Turbo frequency) | 2 | -1.2761 | -1.19891 | -1.06931 |
| Standard error | 2 | 0.4215 | 0.3074 | 0.2869 |
| Ln(Cache) | 0.80131 | 0.60621 | 0.61361 | 0.58481 |
| Standard error | 0.0610 | 0.0721 | 0.0556 | 0.0430 |
| Ln(TDP) | -0.37211 | -0.18921 | -0.20751 | -0.17871 |
| Standard error | 0.0664 | 0.0801 | 0.0670 | 0.0517 |
| Windows | 0.40551 | 0.42311 | 0.44371 | 0.45071 |
| Standard error | 0.0293 | 0.0275 | 0.0237 | 0.0209 |
| Observations | 136 | 148 | 150 | 140 |
| Adjusted R-squared | 0.9866 | 0.9873 | 0.9895 | 0.9919 |
| 1 Statistically significant at the 5-percent level. [2] Omitted from model. Note: CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
| Variable | Q2 2018–Q3 2018 | Q3 2018–Q4 2018 | Q4 2018–Q1 2019 | Q1 2019–Q2 2019 |
|---|---|---|---|---|
| Quarter dummy | 0.0383 | 0.0441 | -0.0018 | -0.0036 |
| Standard error | 0.0240 | 0.0273 | 0.0269 | 0.0273 |
| Ln(Memory) | 0.32661 | 0.26331 | 0.26331 | 0.25871 |
| Standard error | 0.0223 | 0.0189 | 0.0203 | 0.0206 |
| Ln(Storage) | 0.2531 | 0.28061 | 0.26811 | 0.27261 |
| Standard error | 0.0214 | 0.0239 | 0.0275 | 0.0279 |
| SSD | 0.25151 | 0.14651 | 0.15691 | 0.14811 |
| Standard error | 0.0295 | 0.0242 | 0.0265 | 0.0270 |
| Ln(Turbo frequency) | -3.58191 | -1.5151 | -0.96621 | -0.98571 |
| Standard error | 0.3235 | 0.3951 | 0.2928 | 0.2934 |
| Ln(Cache) | 2 | -0.20781 | -0.22661 | -0.24451 |
| Standard error | 2 | 0.0742 | 0.0815 | 0.0826 |
| Ln(TDP) | 0.41971 | 0.6621 | 0.69131 | 0.70731 |
| Standard error | 0.0273 | 0.0639 | 0.0653 | 0.0659 |
| Windows | 0.43791 | 0.40521 | 0.41981 | 0.4211 |
| Standard error | 0.0269 | 0.0247 | 0.0247 | 0.0250 |
| Observations | 132 | 138 | 152 | 152 |
| Adjusted R-squared | 0.9871 | 0.9859 | 0.985 | 0.9846 |
| 1 Statistically significant at the 5-percent level. [2] Omitted from model. Note: CPU = central processing unit; Ln = natural logarithm; SSD = solid-state drive; TDP = thermal design power; Q1 = first quarter; Q2 = second quarter; Q3 = third quarter; Q4 = fourth quarter. Source: U.S. Bureau of Labor Statistics. | ||||
Unlike AWS, there is no major difference between the models with base frequency and the models with turbo frequency. Both sets of models have similar time dummy variables, and the magnitude and sign of base frequency and turbo frequency are similar in the respective models.
For Google Cloud, all of the cloud services in a given region use the same microprocessors. We constructed our dataset from two different regions to provide a mix of microprocessors. From the second quarter of 2017 to the first quarter of 2019, there were no changes in products or prices. With this lack of change, there is no price change for a hedonic model to capture. In the second quarter of 2019, there was a change in the frequency of the microprocessors in one of the regions. We used the statistical learning algorithm with both frequency variables, but in both cases the frequency variables were not selected. Because we know exactly what changed with the cloud services, we estimated models with both frequency variables to see if they yielded any appreciable quality adjusted price change. There was a strong correlation between the region variables and the frequency variables, so we omitted the region variables. Likewise, cache and TDP were strongly correlated, so we omitted TDP. Below are results for the model using base frequency and turbo frequency. The base frequency models evaluated by the statistical learning technique take this form:
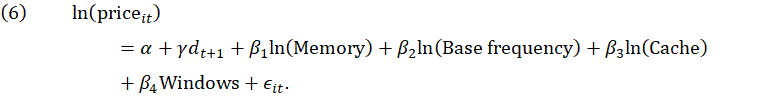
The turbo frequency models take this form:
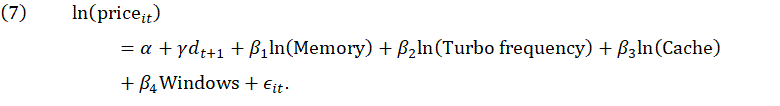
| Variable | Q1 2019–Q2 2019 |
|---|---|
| Quarter dummy | -0.0011 |
| Standard error | 0.0174 |
| Ln(Memory) | 0.18501 |
| Standard error | 0.0087 |
| Ln(Base frequency) | -0.0413 |
| Standard error | 0.3790 |
| Ln(Cache) | 0.81721 |
| Standard error | 0.0102 |
| Windows | 0.50341 |
| Standard error | 0.0142 |
| Observations | 152 |
| Adjusted R-squared | 0.9956 |
| 1 Statistically significant at the 5-percent level. Note: CPU = central processing unit; Ln = natural logarithm; Q1 = first quarter; Q2 = second quarter. Source: U.S. Bureau of Labor Statistics. | |
| Variable | Q1 2019–Q2 2019 |
|---|---|
| Quarter dummy | 0.0003 |
| Standard error | 0.0143 |
| Ln(Memory) | 0.18501 |
| Standard error | 0.0087 |
| Ln(Turbo frequency) | -0.0133 |
| Standard error | 0.0873 |
| Ln(Cache) | 0.81721 |
| Standard error | 0.0102 |
| Windows | 0.50341 |
| Standard error | 0.0142 |
| Observations | 152 |
| Adjusted R-squared | 0.9956 |
| 1 Statistically significant at the 5-percent level. Note: CPU = central processing unit; Ln = natural logarithm; Q1 = first quarter; Q2 = second quarter. Source: U.S. Bureau of Labor Statistics. | |
The models are remarkably similar except for the quarter dummy and frequency coefficients. This similarity suggests that the change in microprocessor frequency in the second quarter of 2019 caused negligible quality adjusted price change and it helps illustrate why the statistical learning algorithm did not select either frequency variable.
Our results show that a time dummy hedonic model can estimate quality adjusted price change for cloud computing services. One of the key drivers of quality change for cloud services is technological improvements in microprocessors. We demonstrate that models using microprocessor characteristics can produce similar results as models using AWS’s ECU measure. This result is important for validating the use of microprocessor characteristics in cloud services models.
We have also applied the statistical learning method used by Sawyer and So. This method of specification selection allows the models to change over time as cloud services change. It also makes our method of choosing a specification transparent to our data users which should bolster the perception of the cloud models. Because the statistical learning method consistently selected most variables, a future hedonic model for cloud services for use in the PPI may just use all variables without being overfit.
If, at a future time, BLS decides to implement a hedonic model for cloud services in the PPI, our work will offer another way to quality adjust prices in the PPI. What will ultimately determine the type of model we use is the data we receive from respondents, but this article validates the use of hedonics for cloud services. This validity is not only shown in the results of the models, but also in the process of collecting data, estimating the models, and interpreting the results. For production use in the PPI, having a viable process for developing a model is necessary for implementation as much as the performance of the model. With a hedonic model for cloud services, BLS will have another method available for PPI estimates that accounts for quality change in an industry that experiences rapid technological progress and has become crucial for the information technology sector.
Steven D. Sawyer, and Claire O'Bryan, "Exploring quality adjustment in PPI cloud computing," Monthly Labor Review, U.S. Bureau of Labor Statistics, February 2023, https://doi.org/10.21916/mlr.2023.4
1 “Gartner forecasts worldwide public cloud end-user spending to grow 23 percent in 2021,” Gartner, April 21, 2021, https://www.gartner.com/en/newsroom/press-releases/2021-04-21-gartner-forecasts-worldwide-public-cloud-end-user-spending-to-grow-23-percent-in-2021.
2 “Gartner forecasts worldwide public cloud end-user spending to grow 18 percent in 2021,” Gartner, November 17, 2020, https://www.gartner.com/en/newsroom/press-releases/2020-11-17-gartner-forecasts-worldwide-public-cloud-end-user-spending-to-grow-18-percent-in-2021.
3 “Quality adjustment in the Producer Price Index” (U.S. Bureau of Labor Statistics, last modified September 20, 2022), https://www.bls.gov/ppi/quality-adjustment/.
4 Industry leaders Amazon Web Services, Microsoft Azure, and Google have publicly available price data for infrastructure as a service (IaaS) packages. The Producer Price Index (PPI) program used this public information to build the data sample for the hedonic model and related research.
5 Jeb Su, “Amazon owns nearly half of the public cloud infrastructure market worth over $32 billion: report,” Forbes, August 2, 2019, https://www.forbes.com/sites/jeanbaptiste/2019/08/02/amazon-owns-nearly-half-of-the-public-cloud-infrastructure-market-worth-over-32-billion-report/#7f7c713d29e0.
6 For IaaS packages, these service characteristics include, but are not limited to, application support and customer support dedicated to the specific package, type of environment (shared versus dedicated or managed), number and speed of microprocessors, type of operating system, amount of memory, data storage, number of users, internet protocal address type (dynamic versus static) and number, computer time used, training, management, and region.
7 Diane Coyle and David Nguyen, “Cloud computing and national accounting,” Economic Statistics Centre of Excellence Discussion Paper 2018–19 (London, UK: Economic Statistics Centre of Excellence, December 19, 2018), https://www.escoe.ac.uk/publications/cloud-computing-and-national-accounting/.
8 Liang Zhang, “Price trends for cloud computing services” (senior thesis, Wellesley College Digital Repository, April 21, 2016), https://repository.wellesley.edu/object/ir1279.
9 Persefoni Mitropoulou, Evangelia Filiopoulou, Stavroula Tsaroucha, Christos Michalakelis, and Mara Nikolaidou, “A hedonic price index for cloud computing services,” in Proceedings of the 5th International Conference on Cloud Computing and Services Science” (Lisbon, Portugal: 5th International Conference on Cloud Computing and Services Science, 2015), pp. 499–505, https://doi.org/10.5220/0005410604990505.
10 Coyle and Nguyen, “Cloud computing and national accounting.”
11 David Byrne, Carol Corrado, and Daniel Sichel, “The rise of cloud computing: minding your P’s, Q’s and K’s,” in Carol Corrado, Jonathan Haskel, Javier Miranda, and Daniel Sichel, eds., Measuring and Accounting for Innovation in the Twenty-First Century (University of Chicago Press, 2020), pp. 519–551, https://www.nber.org/books-and-chapters/measuring-and-accounting-innovation-twenty-first-century/rise-cloud-computing-minding-your-ps-qs-and-ks.
12 To use the estimate of price change from the model in a PPI index, we,
1. Exponentiate e (Euler’s number) to the time dummy coefficient (γ) from the model and then subtract the resulting value by one to represent quality adjusted price change in decimal form:
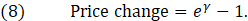
2. Adjust prices for PPI items represented by the model so that those prices change by the amount calculated in step one.
13 “Amazon EC2 FAQs,” Amazon Web Services, Inc., undated, https://aws.amazon.com/ec2/faqs/.
14 Byrne, Corrado, and Sichel, “The rise of cloud computing.”
15 David Byrne, Stephen Oliner, and Daniel Sichel, “How fast are semiconductor prices falling?,” Review of Income and Wealth vol. 64, no. 3 (September 2018), pp. 679–702, https://doi.org/10.1111/roiw.12308.
16 For definitions of these terms and for further details, see Steven D. Sawyer and Alvin So, "A new approach for quality-adjusting PPI microprocessors," Monthly Labor Review, December 2018, https://doi.org/10.21916/mlr.2018.29.
17 Sawyer and So, "A new approach for quality-adjusting PPI microprocessors.”
18 Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani, An Introduction to Statistical Learning: With Applications in R, Springer Texts in Statistics, vol. 103 (New York, NY: Springer, 2013), https://doi.org/10.1007/978-1-4614-7138-7.
19 The process of k-fold cross validation can be described in a few steps:
1. Split dataset into k parts,
2. Hold out one of the k parts and estimate the models on the remaining parts,
3. Use models estimated in step two to predict prices for observations in k part,
4. Square the difference between predicted prices and actual prices from the dataset,
5. Hold out each of the k parts in turn and repeat steps one through three,
6. Repeat process multiple times but split the data differently each time,
7. Take average of squared errors to calculate mean squared error (MSE),
8. Model with lowest MSE is selected.
20 Sawyer and So, "A new approach for quality-adjusting PPI microprocessors.”
21 See Timothy Erickson “On 'incorrect' signs in hedonic regression” Working Paper 490 (U.S. Bureau of Labor Statistics, July 2016), https://www.bls.gov/osmr/research-papers/2016/pdf/ec160050.pdf.