
An official website of the United States government
An official website of the United States government
The .gov means it's official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information,
make sure you're on a federal government site.
The site is secure.
The
https:// ensures that you are connecting to the official website and that any
information you provide is encrypted and transmitted securely.
The Producer Price Index (PPI) program measures the average change over time in the selling prices received by domestic producers for their output. The prices included in the PPI are from the first commercial transaction for many products and some services.
PPI for final demand components, 1-month percent change, June 2026
Commodity
1-month percent change
Goods
-1.4%
Foods
-0.6%
Fresh fruits and melons
-2.2%
Fresh and dry vegetables
-6.0%
Meats
-0.7%
Processed poultry
-2.5%
Dairy products(1)
0.7%
Soft drinks(1)
0.2%
Energy
-6.4%
Residential electric power
0.7%
Residential natural gas
1.2%
Gasoline
-12.0%
Jet fuel(1)
-17.2%
Home heating oil and distillates
-8.2%
No. 2 diesel fuel
-18.0%
Goods less foods and energy
0.2%
Industrial chemicals
-0.8%
Pharmaceutical preparations(1)
-0.1%
Passenger cars
0.2%
Trucks, 14,000 lbs. and under
-0.1%
Aircraft and aircraft equipment
0.1%
Cigarettes, including nontobacco(1)
0.0%
Services
0.2%
Trade services
0.4%
Machinery and equipment and parts and supplies wholesaling(1)
-4.5%
Food and alcohol retailing
1.0%
Health and beauty retailing, including optical goods(1)
0.1%
Apparel, jewelry, footwear, and accessories retailing
3.6%
Automobiles and automobile parts retailing
0.8%
Fuels and lubricants retailing
13.0%
Transportation and warehousing services
-0.1%
Rail transportation of freight and mail(1)
0.0%
Truck transportation of freight(1)
0.0%
Water transportation of freight(1)
0.3%
Air transportation of freight(1)
0.3%
Courier, messenger, and U.S. postal service
-0.5%
Airline passenger services
-0.4%
Less trade, transportation, and warehousing
0.1%
Loan services (partial)
5.7%
Securities brokerage, dealing, investment advice, and related services(1)
3.1%
Portfolio management(1)
0.5%
Outpatient care (partial)
0.0%
Inpatient care
0.4%
Traveler accommodation services
-1.0%
Footnotes
(1) Not seasonally adjusted.
Note: All data are subject to revision up to 4 months after originally published.
Total
-1.4%(p) in Jun 2026
![]()
Foods
-0.6%(p) in Jun 2026
![]()
Energy
-6.4%(p) in Jun 2026
![]()
Core goods
+0.2%(p) in Jun 2026
![]()
Total
+0.2%(p) in Jun 2026
![]()
Transportation and warehousing
-0.1%(p) in Jun 2026
![]()
Trade
+0.4%(p) in Jun 2026
![]()
Other
+0.1%(p) in Jun 2026
![]()
Construction
+0.1%(p) in Jun 2026
![]()
Processed goods
-1.2%(p) in Jun 2026
![]()
Unprocessed goods
-4.1%(p) in Jun 2026
![]()
Services
+0.3%(p) in Jun 2026
![]()
Stage 4 intermediate demand
-0.1%(p) in Jun 2026
![]()
Stage 3 intermediate demand
unchanged in Jun 2026
![]()
Stage 2 intermediate demand
-1.2%(p) in Jun 2026
![]()
Stage 1 intermediate demand
-0.5%(p) in Jun 2026
![]()
Motor vehicles
-0.1%(p) in Jun 2026
![]()
Pharmaceutical preparations
-0.1%(p) in Jun 2026
![]()
Gasoline
-12.0%(p) in Jun 2026
![]()
Meats
-0.7%(p) in Jun 2026
![]()
Industrial chemicals
-0.8%(p) in Jun 2026
![]()
Lumber
+1.3%(p) in Jun 2026
![]()
Steel mill products
+3.6%(p) in Jun 2026
![]()
Diesel fuel
-18.0%(p) in Jun 2026
![]()
Prepared animal feeds
+0.9%(p) in Jun 2026
![]()
Crude petroleum
-12.1%(p) in Jun 2026
![]()
Grains
-12.0%(p) in Jun 2026
![]()
Carbon steel scrap
+4.0%(p) in Jun 2026
![]()
Outpatient healthcare
unchanged in Jun 2026
![]()
Inpatient healthcare services
+0.4%(p) in Jun 2026
![]()
Food and alcohol retailing
+1.0%(p) in Jun 2026
![]()
Apparel and jewelry retailing
+3.6%(p) in Jun 2026
![]()
Airline passenger services
-0.4%(p) in Jun 2026
![]()
Securities brokerage, dealing, investment, and related services
+3.1%(p) in Jun 2026
![]()
Business loans (partial)
+6.0%(p) in Jun 2026
![]()
Legal services
+0.5%(p) in Jun 2026
![]()
Truck transportation of freight
unchanged in Jun 2026
![]()
Machinery and equipment wholesaling
-4.5%(p) in Jun 2026
![]()
07/15/2026
The Producer Price Index for final demand fell 0.3 percent in June. Prices for final demand
goods decreased 1.4 percent, and the index for final demand services moved up 0.2 percent.
Prices for final demand increased 5.5 percent for the 12 months ended in June.
HTML
|
PDF
|
RSS
|
Charts
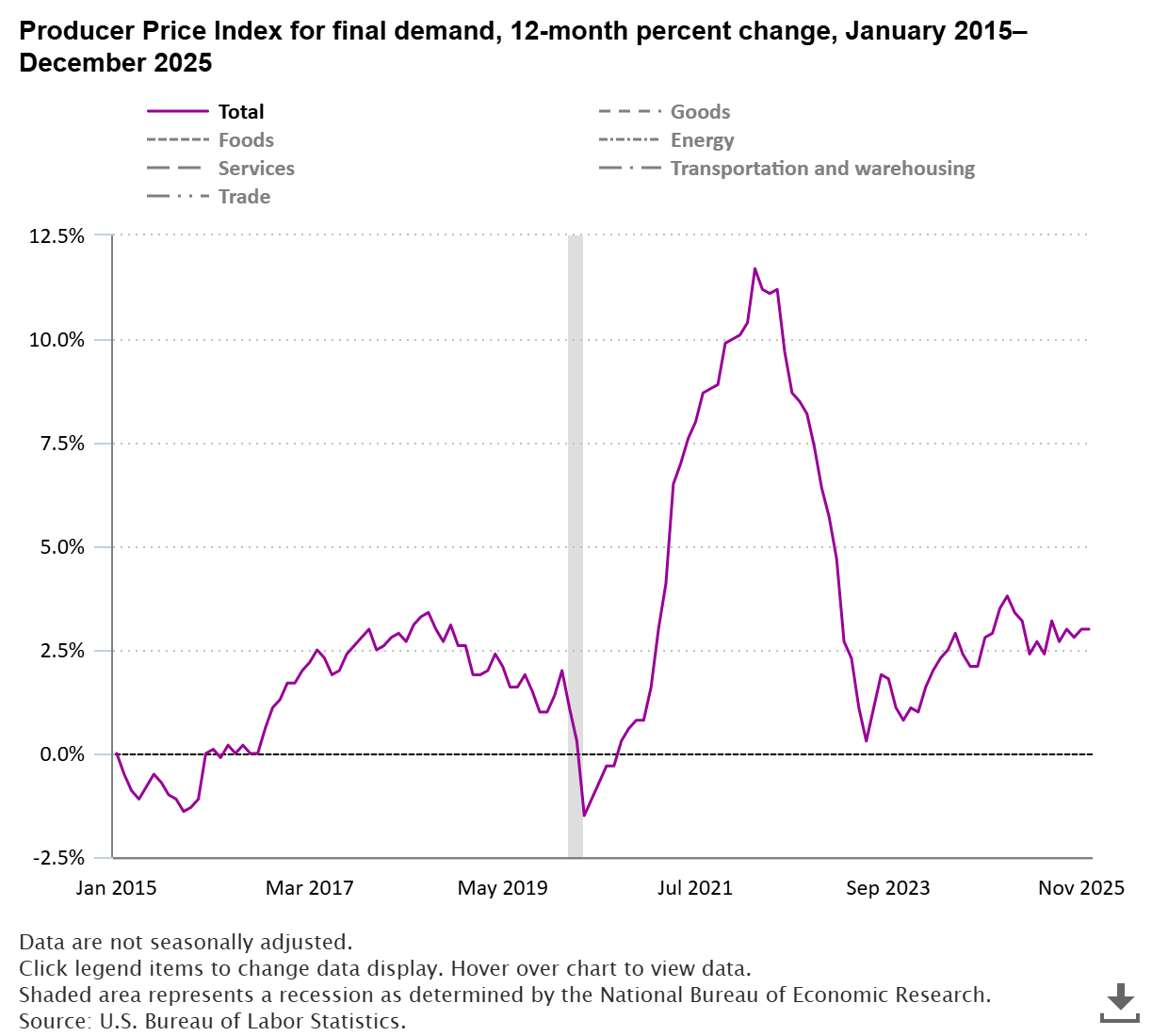
The Producer Price Index for final demand increased 3.0 percent in 2025 after rising 3.5 percent in 2024. Producer prices for goods rose 2.5 percent in 2025, while prices for services increased 3.2 percent. read more »

This Beyond the Numbers article will examine the price movement of steel in three phases: March 2020–August 2020, when the pandemic shock set in and steel prices fell; September 2020–December 2021, when the economy began to rebuild and steel prices surged; and January 2022–May 2023, when economic activity expanded but steel prices generally moved lower. read more »

This Spotlight on Statistics reviews historical establishment, employment, and wage trends for the amusement and theme parks industry. Additionally, productivity, consumer expenditures for entertainment fees and admissions, and producer prices for select amusement and theme parks products are reviewed. read more »